#dat
I use three main tags on this blog:
-
hypertext: linking, the Web, the future of it all.
-
garage: art and creation, tinkering, zines and books, kind of a junk drawer - sorry!
-
elementary: schooling for young kids.


#dat
I use three main tags on this blog:
hypertext: linking, the Web, the future of it all.
garage: art and creation, tinkering, zines and books, kind of a junk drawer - sorry!
elementary: schooling for young kids.

I’m happy to say that Duxtape is has returned to Beaker Browser. Hide your mixtapes here. hyper://5b6920…e0/.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
How to distribute 255GB of HTML and still make it browsable.
This is sick. The Dat team is benchmarking 2.0 using a dump of Wikipedia. One peer is seeding the whole archive—the peer in the video is selectively downloading files. And pages are rendered in a few seconds.
@pfrazee:
The total archive is 255GB of content with 5GB of internal metadata. This browsing session pulled down 3mb of the metadata and 6mb of content to the local device. (Again, this bench is showing the site get served fresh over the lan from another device.)
The innovation here is the new hash-trie index, which was laid out by Mathias Buus in the recent talk at Data Terra Nemo.
To me, this is reassuring. Beaker has really made progress toward becoming a stable peer-to-peer web browser—and to see them hustling on performance, working to improve the fundamentals—gives me great confidence. I can’t see Beaker becoming mainstream, but I think it could be tremendously useful to everyone else: artists, archivers, the underground—not in a ‘dark web’ sense, but in the sense of those who want to experiment and innovate outside of the main network.[1]
Anyway—just want to encourage this work. This team is really pouring work into the protocol. Happy to give them some kudos.
In fact, maybe what could happen here is just that there could be a kind of Web between the centralized one and the ‘dark’ one. Fully anonymized networks just have such a target on their heads. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

Ok, I thought I had really polished Duxtape up as much as I could. And now I’m realizing that many will close Beaker before their mixtape is fully seeded. It’d be nice to indicate if the full mixtape is available on the network. I was only able to grab 53% of the i, cactus one.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

My teardown of Beaker and the Dat network.
We’re probably all scrambling to figure out a future for ourselves—either by hunting around for some shred of promising technology or by throwing up our hands—shouting and retreating and dreading the shadow of the next corporate titan descending from the sky. The prolonged lifespans of distributed protocols like Bitcoin and torrents means we’re maybe skeptical or jaded about any new protocols—these types of protocols are becoming old news. Maybe we’re just hunkered down in some current online bucket.
And I’ve felt this too—ActivityPub and Secure Scuttlebutt are too complicated. Tim Berner-Lee’s Solid is—well, I can’t even tell what it is. I don’t want to hear about blockchain: do we really need a GPU mining war at the center of our new Web? These are all someone’s idea of a distributed Web, but not mine. IPFS is really cool—but how do I surf it?
After discovering the Beaker Browser, a Web browser for the distributed Dat network, I felt that there was some real promise here. It was simple—load up the browser, create a website, pass your link around. There’s not much new to learn. And the underlying technology is solid: a binary protocol very similar to Git.[1] (As opposed to Secure Scuttlebutt, which is tons of encrypted JSON.)
I spent four months using Beaker actively: running this website on the network, messing with the different libraries, trying out the different apps—and then I hit a wall. Had a good time, for sure. And I kept seeding my Dats—kept my sites on the network. The technology was just lovely.
But: you can’t yet edit a website from a different browser (like on a different computer). This is called multi-writer support—and there is some talk about this landing by the end of the year. But this is, from what I can see, the single major omission in Beaker. (It’s not a problem with Dat itself—you can use a Hyperdb for that—but Beaker hasn’t settled the details.)
So I left Dat alone. I figured: they need time to work this problem out. Beaker has remained remarkably effortless to use—I’d hate for multi-writer to be tacked on, complicating the whole thing.
Recently, it occured to me that maybe I don’t need multi-writer. And maybe I should really be sure that the rest of Dat is as perfect as I think it is. So I started working on a limited (but full-featured) app for Beaker, with the intention of writing up a full ‘review’/‘teardown’ of everything I discover in the process.
This is my review—and the app is Duxtape.
It occured to me that a Muxtape clone would be a perfect tracer bullet for me to push Beaker. (Muxtape was a 2008 website for sharing mixtapes—minimal design, suddenly became very prominent, and then was promptly DEMOLISHED by the music industry.)
Muxtape was shut down because it was centralized. If Muxtape had been distributed[2], it would be much more difficult (perhaps impossible) to shutter.
Muxtape did some file processing. Reading music file metadata (title, artist’s name) and loading music into the browser’s music player. Could the app handle this?
The Muxtape home page listed recent mixtapes. This would give me a chance to use datPeers—a way of talking to others that are using the same site.
Storing song information and order. I don’t have a database, so where do I put this stuff?
A more general question: What if I upgrade the code? How do I handle upgrading the mixtapes too?
I also didn’t want to think in terms of social networks. Many of Beaker’s most advanced apps (like Fritter and Rotonde) are ‘messaging’/‘social’ apps. I specifically wanted a creation tool that spit out something that was easy to share.
How would Beaker do with that kind of tool?
Ok, so how does Dat work exactly? It is simply a unique address attached to a folder of files (kind of like a ZIP file.) You then share that folder on the network and others can sync it to their system when they visit the unique address.
In the case of Duxtape, the address is dat://df1cc…40.

The full folder contents can be viewed here at datBase.
So when you visit Duxtape, all that stuff is downloaded. Beaker will show you the index.html, which simply lets you create a new mixtape and lists any that you’ve encountered.
Now, you can’t edit my Dat—so how do you create a mixtape?? And how does it keep track of other mixtapes?? Teardown time!
This creates a new Dat (new folder on your computer) with just index.html inside. I actually copy the tape.html from my Dat into that folder, your mixtape. That HTML file will load its images and Javascript and such from MY Duxtape dat! (This means I can upgrade my original Dat—and upgrade YOUR Dat automatically—cool, but… dangerous.)
When you hit someone else’s mixtape link, the Javascript loads the Duxtape home page in an HTML iframe—passing the link to that page. The link is then stored in ‘localStorage’ for that page. So, those are kept in a kind of a cookie. Nothing very server-like about any of that.
But furthermore: when you are on the Duxtape homepage, your browser will connect to other browsers (using datPeers) that are viewing the homepage. And you will trade mixtapes there. Think about this: you can only discover those who happen to be around when you are! It truly acts like a street corner for a random encounter.
Where are song titles and song ordering kept? Well, heh—this is just kept in the HTML—in your index.html. Many Beaker apps keep stuff like this in a JSON file. But I felt that there was no need for duplication. (I think the IndieWeb has fully corrupted me.) When I want to read the mixtape title, I load the index.html and find the proper tags in the page. (Like: span.tape-title, for instance.)
Beaker has a special technique you can use for batching up edits before you publish them. (See the checkout method.) Basically, you can create a temporary Dat, make your changes to it, then either delete it or publish it.
However, I didn’t go this route. It turned out that I could batch up all my changes in the browser before saving them. This includes uploaded files! I can play files in the browser and read their data without copying them to the Dat. So no need to do this. It’s a neat feature—for a different app.
So this allows you to work on your mixtape, add and delete songs, get it perfect—then upload things to the network.[3]
This all worked very well—though I doubt it would work as well if you had 1,000 songs on your mixtape. In that case, I’d probably recommend using a database to store stuff rather than HTML. But it still might work well for 1,000 songs—and maybe even 1,000,000. This is another advantage to not having a server as a bottleneck. There is only so much that a single person can do to overload their browser.
For reading song metadata, I used the music-metadata-browser library—yes, I actually parse the MP3 and OGG files right in the browser! This can only happen in modern times: Javascript has become a competent technology on the server, now all of that good stuff can move into the browser and the whole app doesn’t need a server—in fact, WebAssembly makes Dat even more compelling.
Lastly, here are some calls that I used which are specific to the Beaker Browser—these are the only differences between running Duxtape in plain Chrome and running it distributed:
stat: I use this to check if a song file has already been uploaded.
readFile: To read the index.html when I need to get song information.
writeFile: To save changes to songs—to publish the index.html for your mixtape.
unlink: To delete songs—NOTE: that songs are still in the Dat’s history and may be downloaded.
getInfo and configure: Just to update the name of the mixtape’s Dat if the name of the mixtape is changed by you. A small touch.
isOwner: The getInfo() above also tells me if you are the owner of this mixtape. This is crucial! I wanted to highlight this—I use this to enable mixtape editing automatically. If you don’t own the mixtape, you don’t see this. (All editor controls are removed when the index.html is saved back to disk.)
So this should give you a good idea of what Dat adds. And I just want to say: I have been wondering for awhile why Dat has its own special format rather than just using something like Git. But now I see: that would be too complex. I am so glad that I don’t have to pull() and commit() and all that.
I spent most of my time working on the design and on subtle niceties—and that’s how it should be.
It’s clear that there are tremendous advantages here: Dat is apps without death. Because there is no server, it is simple to both seed an app (keep it going) and to copy it (re-centralize it). I have one central Duxtape right now (duxtape.kickscondor.com), but you could easily fork that one (using Beaker’s ‘make editable copy’ button) and improve it, take it further.
The roots of ‘view source’ live on, in an incredibly realized form. (In Beaker, you can right-click on Duxtape and ‘view source’ for the entire app. You can do this for your mixtapes, too. Question: When was the last time you inspected the code hosting your Webmail, your blog, your photo storage? Related question: When was the first time?)
In fact, it now becomes HARD:IMPOSSIBLE to take down an app. There is no app store to shut things down. There is no central app to target. In minutes, it can be renamed, rehashed, reminified even (if needed)—reborn on the network.
This has a fascinating conflict with the need to version and centralize an app. Many might desire to stay with the authoritative app—to preserve their data, to stay in touch with the seeders of that central app. But this is a good tension, too—it INSISTS on backwards compatibility. I am pressured to keep Duxtape’s conventions, to preserve everyone’s mixtapes. It will be difficult to upgrade everything that is possibly out there.
This same pressure is reminiscent of the Web’s own history: HTML that ran in 1995 often still runs today—Flash and Quicktime are quite the opposite, as will be all of the native apps of today. (Think of apps you’ve bought that are already outmoded.) The ‘view source’ keeps compatibility in check. If Beaker is able to keep their APIs firm, then there is real strength here.
Still, Dat is limited. Where is it short? Can we accept these?
But—think about this: I don’t have to take on cloud hosting! I don’t need to scale the app! This is a huge relief. URGENT QUESTION: Why are we trying to even do this?
I also mentioned not needing the multi-writer feature. Obviously, multi-writer demands some centralization. A central Dat needs to authorize other Dats. But I think this centralization could be moved to the DNS resolution—basically, if I edit Duxtape on a second machine, it will have a new unique address—and I can point duxtape.kickscondor.com to that new address. This means I can never get locked out of the Dat—unless I am locked out of the DNS. (So there is a way forward without any new features.)
Still, these downsides are pure side effects of a distributed Web. These are the realities we’re asking for—for me, it’s time to start accepting them.
Several months had passed since I last used Dat—how was it doing with adoption?
Well, it seems, no different. But it’s hard to say for a distributed network. Every Dat runs in secret—they are difficult to find. The discovery problems are perhaps the most urgent ones.
But there is good recent work:
These are all cool—but Dat has a long way to go. With the corpypastas taking up all the attention, adoption is terribly slow. What Beaker may need most of all is a mobile version. But, hey, I’ll write my article here and make my dent—if you feel stimulated to noise about, then please join in. I mean: using a new web browser is just very low effort—perhaps the lowest. You need to use one anyway!
I think HTTPS has proven itself well for the centralized stuff. Perhaps there is a future for HTTPS as simply a collection of centralized REST APIs for things like search and peer discovery. I think the remaining apps could migrate to this fertile garden emerging on the Dat network.
It should be noted that there is a document called “How Dat Works”, which goes into all the details and which is absolutely beautiful, well-organized and, yeah, it actually teaches you very plainly how Dat works! I am not sure I’ve seen such a well-made ‘white paper’/‘spec’-type doc. ↩︎
Apps on the Dat network have no ‘server’, they can be seeded like any other file. ↩︎
Clearly Dat apps will need to put extra work into providing a scratch area for draft work—the protocol puts this pressure on the app. I think this also makes the system lean toward single-page apps, to assist drafting when in a large app. ↩︎
I would be REALLY interested in seeing an equivalent to The Pirate Bay on Beaker. If you could move a tracker to the Dat network, much would be learned about how to decentralize search. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I’m sorry… another project…
While messing with Dat last night, I got carried away in nostalgia and began… recreating Muxtape in Dat. I wanted to see how far I could get. (If you don’t know what Muxtape was—it was a way of sharing mp3 mixtapes online for a brief window of time in 2008, until it was shut down by the grown-ups.)
So, it seemed interesting to try to replicate Muxtape, because it would be very hard to “shut down” on the Dat network. And, sure enough, I was able to get it working quite well: you can upload songs, tweak the colors and titles, order the songs and such—I think this is quite faithful.
And, yes, it’s peer-to-peer. You can edit your tape using the URL created for you. Then you can pass that same URL out to share your tape. Visitors can listen to the music and seed the tape for everyone else.
If you’re interested in seeing what a mix looks like, try: hyper://61477c44…1c/. (You’ll need Beaker.)
Source code is here. Inspired by Tara Vancil’s dat-photos-app. Thanks, Tara!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Idea: gang up to cache classic websites.
This is just a zygotic bit of a thought that I’ve been having. A group that would band together to share classic websites (likely on the ‘dat’ network), perhaps as if they were abandonware or out-of-print books. Many of the early net.art sites have been kept up because they have university support; many other sites disappear and simply don’t function on The Internet Archive.
(To illustrate how even a major art piece can go down, Pharrell’s 24 Hours of Happy interactive music video—yeah. that link is broken. You can see kind of see it on YouTube, but… the hypertext enthusiast in me wants to see it live on in its original form.)
Some sites that I really need to reconstruct:
Room of 1,000 Snakes. This game hasn’t been playable for a year or two now. I promised a friend I would work on this. (This is an issue with Unity Web Player going defunct.)
The Woodcutter. Careful, redirects. This site was a huge deal for me when I was younger. When I started href.cool, it was fine—and had been fine for like fifteen years!—and then it suddenly broke. I think it can be reconstructed from The Internet Archive.
Fly Guy. Moved to the App Store??
SARDINE MAGOZINE. Charlie is gone now—so I’ve already started doing this.
SMASH TV. This suddenly disappeared recently, but I think it’s been restored to YouTube now—I need my copies.
Sites I need to back up; feels like their day is nigh:
1080plus. I’ve already been through losing this once.
Bear Stearns Bravo. Yeah, I think so. (This Is My Milwaukee could be recreated too.)
“Like a Rolling Stone.” Similar story to “24 Hours of Happy”—this kind of disappears for months at a time, but seems to work as of March 2019.
Frog Fractions. This one is probably too adored to disappear—still.
Everything in my Real/Person category. These personal pages can easily float away suddenly.
Of course, I’d love to get the point where I have a cached copy of everything at href.cool—there are several Tumblrs in there and Blogspots. I’m not as worried with those, because The Internet Archive does a fine job of keeping them relatively intact. But if a YouTube channel disappears, it’s gone to us.
Along similar lines, I have been trying to message the creators of the Byte app—not the hyped Vine 2, but the original Byte that was basically like an underground vaporwave social network from 2014-2016. I want to secure a dump of the public Bytes from that era. It was sick.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A prototype for the time being.
I’m sorry to be very ‘projecty’ today—I will get back to linking and surfing straightway. But, first, I need to share a prototype that I’ve been working on.
Our friend h0p3[1] has now filled his personal, public TiddlyWiki to the brim—a whopping 21 MEGAbyte file full of, oh, words. Phrases. Dark-triadic memetic, for instance. And I’m not eager for him to abandon this wiki to another system—and I’m not sure he can.
So, I’ve fashioned a doorway.
This is not a permanent mirror yet. Please don’t link to it.

Yes, there is also an archive page. I took these from his Github repo, which appears to go all the way back to the beginning.
Ok, yes, so it does have one other feature: it works with the browser cache. This means that if you load snapshot #623 and then load #624, it will not reload the entire wiki all over again—just the changes. This is because they are both based on the same snapshot (which is #618, to be precise.) So—if you are reading over the course of a month, you should only load the snapshot once.
Snapshots are taken once the changes go beyond 2 MB—though this can be tuned, of course.
Shrunk to 11% of its original size. This is done through the use of judicious diffs (or deltas). The code is in my TiddlyWiki-loader repository.
I picked up this project last week and kind of got sucked into it. I tried a number of approaches—both in snapshotting the thing and in loading the HTML.
I ended up with an IFRAME in the end. It was just so much faster to push a 21 MB string through IFRAME’s srcdoc property than to use stuff like innerHTML or parseHTML or all the other strategies.
Also: document.write (and document.open and document.close) seems immensely slow and unreliable. Perhaps I was doing it wrong? (You can look through the commit log on Github to find my old work.)
I originally thought I’d settled on splitting the wiki up into ~200 pieces that would be updated with changes each time the wiki gets synchronized. I got a fair bit into the algorithm here (and, again, this can be seen in the commit log—the kicksplit.py script.)
But two-hundred chunks of 21 MB is still 10k per chunk. And usually a single day of edits would result in twenty chunks being updated. This meant a single snapshot would be two megs. In a few days, we’re up to eight megs.
Once I went back to diffs and saw that a single day usually only comprised 20-50k of changes (and that this stayed consistent over the entire life of h0p3’s wiki,) I was convinced. The use of diffs also made it very simple to add an archives page.
In addition, this will help with TiddlyWikis that are shared on the Dat network[2]. Right now, if you have a Dat with a TiddlyWiki in it, it will grow in size just like the 6 gig folder I talked about in the last box. If you use this script, you can be down to a reasonable size. (I also believe I can get this to work directly from TiddlyWiki from inside of Beaker.)
And, so, yeah, here is a dat link you can enjoy: dat://38c211…a3/
I think that’s all that I’ll discuss here, for further technical details (and how to actually use it), see the README. I just want to offer help to my friends out there that are doing this kind of work and encourage anyone else who might be worried that hosting a public TiddlyWiki might drain too much bandwidth.
philosopher.life, dontchakno? I’m not going to type it in for ya. ↩︎
The network used by the Beaker Browser, which is one of my tultywits. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
The issues with Dat as an e-mail analogue.
Perhaps Dat simply isn’t designed for privacy—but it’s so close that I think it’s very useful to talk about the gaps. This is a very solid list of how Dat measures up for private groups—compared to an e-mail newsletter.
It seems to me that the main sticking point is that Dat is always accessible to the main network, whereas e-mail is inaccessible to the main network (except through windy routes.)
It occurs to me that maybe this is what Hyperswarm (a project by some of the Dat team) is attempting to add. If you can run a private Dat network, then you could have a shared folder detached from the main network that would be inaccessible. You’d probably need a password on top of that—but that seems analogous to, say, IMAP. You’d still need tools to access it, so it’s all entirely hypothetical, but yeah—cool thoughts, thank you!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
An incredibly sick tool for archiving—maybe this is already popular and beloved, but it doesn’t hurt to wave it around a bit here.
A modern WWW archiver service—just was overhauled and the bleeding-edge can save the archive to Dat. (Makes me want a ‘record’ ⏺ button in my URL bar that I can just leave on! Any ideas if this exists??)
(INCIDENTALLY discovered this on the Code for Society Agenda notes on Etherpad, which I hadn’t seen in many years—it’s fantastic that it’s still around! This is a tool surely in the vein of what our little internet surf club here has been discussing recently. (Video here, haven’t watched this, so this is also a TODO.)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This is a technical overview of how to use/understand Dat. It covers how useful it is for ‘backing up’ websites—which is how I intend to use it.
So, this article (and the comments) cleared up a few things for me.
Dat can currently be configured to either track all changes (history) of files in a folder (at the cost of a full duplication of all files and all historical changes), or track only the most recent version of files with no duplication (at the cost of losing all history). There is not (yet?) any fancy dat mode which efficiently tracks only deltas (changes) to files with no other file overhead.
From my examination of the Beaker code yesterday, I noticed that the browser only downloads the specific version of a file that you need—I like this! (Rather than having to download the whole history of a file to put it back together.)
One advantage that Dat has over IPFS is that it doesn’t duplicate the data. When IPFS imports new data, it duplicates the files into ~/.ipfs. For collections of small files like the kernel, this is not a huge problem, but for larger files like videos or music, it’s a significant limitation. IPFS eventually implemented a solution to this problem in the form of the experimental filestore feature, but it’s not enabled by default. Even with that feature enabled, though, changes to data sets are not automatically tracked. In comparison, Dat operation on dynamic data feels much lighter. The downside is that each set needs its own dat share process.
I think this is a great benefit of Dat’s design. Because it basically just boils down to a distributed append-only log—a giant, progressively longer file that many people can share, and which you can build stuff like file folders or a database on top of—it’s incredibly flexible.
It certainly has advantages over IPFS in terms of usability and resource usage, but the lack of packages on most platforms is a big limit to adoption for most people. This means it will be difficult to share content with my friends and family with Dat anytime soon, which would probably be my primary use case for the project.
I totally disagree with this sentiment! Dat has the Beaker Browser—which is an incredible thing for a novice to use. Yes, it would (will?) be even better when it can be found on iOS and Android. But, for now, I’m happy to recommend it to friends and family: “Yeah, you can share your own websites—we can even have our own private Twitter-type-thing together—with this thing.”
I know the Beaker team has said that their goal is to get Dat accepted by the major browsers—but I think Beaker’s ability to customize itself to the decentralized web is an advantage. I could see it finding a lot of users.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A proof-of-concept for enjoying HTML includes.
It seems like the Beaker Browser has been making an attempt to provide tools so that you can create JavaScript apps that function literally without a server. Their Twitter-equivalent (‘fritter’) runs entirely in the browser—it simply aggregates a bunch of static dats that are out there. And when you post, Beaker is able to write to your personal dat. Which is then aggregated by all the others out there.
One of the key features of Beaker that allows this is the ‘fallback_page’ setting. This setting basically allows for simplified URL rewriting—by redirecting all 404s to an HTML page in your dat. In a way, this resembles mod_rewrite-type functionality in the browser!
What I’ve been wondering is: would it be possible to bring server-side includes to Beaker? So, yeah: browser-side includes. My patch to beaker-core is here. It’s very simple—but it works!
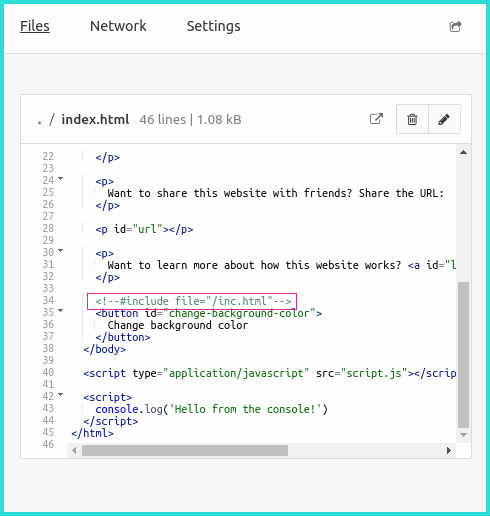
Here is Beaker editing the index.html of a new basic Website from its template. I’m including the line:
<!--#include file="inc.html"-->
This will instruct beaker to inline the inc.html contents from the same dat archive.
Its contents look like this:
<p style="color:red">TEST</p>
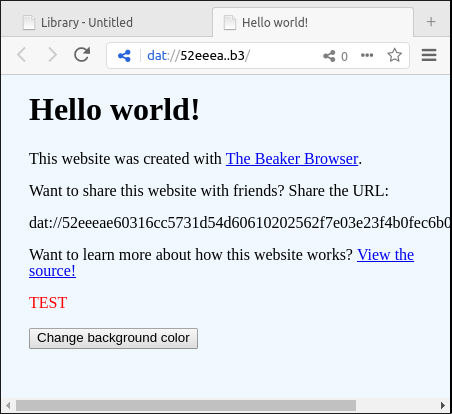
And here we see the HTML displayed in the browser.
I’m not sure. As I’ve been working with static HTML in dat, I’ve thought that it would be ‘nice’. But is ‘nice’ good enough?
Here are a few positives that I see:
Appeal to novices. Giving more power to HTML writers can lower the bar to building interesting things with Dat. Beaker has already shown that they are willing to flesh out JavaScript libraries to give hooks to all of us users out here. But there are many people who know HTML and not JavaScript. I think features for building the documents could be really useful.
Space savings. I think static blogs would appreciate the tools to break up HTML so that there could be fewer archive changes when layouts change subtly.
Showcase what Beaker is. Moving server-side includes into Beaker could demonstrate the lack of a need for an HTTP server in a concrete way. And perhaps there are other Apache/Nginx settings that could be safely brought to Beaker.
The negative is that Dat might need its own wget that understands a feature
like this. At any rate, I would be interested if others find any merit to
something like this. I realize the syntax is pretty old school—but it’s
already very standard and familiar, which seems beneficial.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

glitchyowl, the future of 'people'.
jack & tals, hipster bait oracles.
maya.land, MAYA DOT LAND.
hypertext 2020 pals: h0p3 level 99 madman + ᛝ ᛝ ᛝ — lucid highly classified scribbles + consummate waifuist chameleon.
yesterweblings: sadness, snufkin, sprite, tonicfunk, siiiimon, shiloh.
surfpals: dang, robin sloan, marijn, nadia eghbal, elliott dot computer, laurel schwulst, subpixel.space (toby), things by j, gyford, also joe jenett (of linkport), brad enslen (of indieseek).
fond friends: jacky.wtf, fogknife, eli, tiv.today, j.greg, box vox, whimsy.space, caesar naples.
constantly: nathalie lawhead, 'web curios' AND waxy
indieweb: .xyz, c.rwr, boffosocko.
nostalgia: geocities.institute, bad cmd, ~jonbell.
true hackers: ccc.de, fffff.at, voja antonić, cnlohr, esoteric.codes.
chips: zeptobars, scargill, 41j.
neil c. "some..."
the world or cate le bon you pick.
all my other links are now at href.cool.



{kind=link}
Reply: Cubit and Tribler
Hey, thank you for the leads! I think what Dat could add is the ability to run your own custom tracker—in fact, I don’t even know if there would be a need for that. You could just put a simple web page up on Dat with your magnet links.
I’ll have to give Tribler a shot to see how smooth it is. In a way, we’ve seen this kind of thing before with the built-in search for networks like Soulseek and eDonkey2000 and such. I guess even Napster had that initially.