14 Dec 2018
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.


This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

(Joe’s full article is here.)
Yes, here we are again—I think what you’re saying is that even a single-line annotation of a link, even just a few words of human curation do wonders when you’re out discovering the world. (Perhaps even more than book recommendations—where we know that at least we can rely on certain publishers and editors to vet their publications—I’m a big fan of the Dalkey Archive[1], for instance—but we have no idea the quality of writings out on the Internet at large and are desperately reliant on these annotations in the field.)
Pinboard is doing everything right in that regard—of course, it cribs from Delicious before it—giving hyperlinkers an appropriate amount of meta-dressing to put around their link: tags, description, search tools. However, it misses out on the kind of visual styling and layouts that you, Joe, get to enjoy. (I really like how you batch up links for the day, similar to how h0p3 does it.)
I think another of my lingering questions is: what are we really doing here? When I look at h0p3’s links, he’s trying to catalog his discoveries for the day completely—at least, I don’t think he edits this list. You also mention in your essay that you ‘curate links for my own ongoing use’. Whereas I tend to ‘advertise’ links more, to bring attention to the parts of the web that I want to survive.
So it’s more natural for me to work towards a final directory of links, a hub of all the nodes that I want to see connected. I want these individuals to be aware of each other. I see your Linkport as being a type of directory; I wonder to what extent you are doing this as well—and I wonder what kinds of collaborations we could get going between our directories. You do say that ‘people finding me and finding some of my links enjoyable’ is a secondary goal. I guess another angle I keep alluding to is the benefit you give to the authors behind the links you’re publishing—this type of work is a tremendous gift to them.
Along these lines: I see link duplication as being an interesting thing—clearly we don’t all just want the same links, but I think it will be interesting to see how much overlap there is. I also really like, for example, when David Crawshaw’s article last week got linked by h0p3, Brad, Eli, other microbloggers—it made me feel like we were trying to send some kind of concentrated transmission to the author—linking as a greeting, links as an invitation.
With time, many personal sites and blogs disappeared from the web as people flocked to the big silos where their content became a heavily monitized commodity. To me, the web had lost much of its soul as people gathered in just a few, huge noise chambers. […]
Current trends and a rebirth of personal blogging certainly make the type of curation I do much easier, thank you. Had it not been for that stimulating conversation, I probably would not have been writing this.
It’s interesting to me that the corpypastas had this kind of effect. Because they actually eased publishing and participation for so many people. Facebook is a type of gated community—so I see why it had this kind of effect. But it’s interesting that Twitter and Instagram also dampened the growth of the web. I hazard that perhaps this was simply because their game was best played by their rules—an external link to Twitter wouldn’t show up in your ‘likes’ whereas a like from another tweet was fully realized by the author and the… err… liker.
And I don’t want to chalk this up to mere ego—the author and the liker could see each other from across the Internet. And that is valuable. This is also what micro.blog is assisting us with—we have our blogs, but it is a useful capsule pipeline, so that we can get to each other clearly. (This is why I’m not just linking to your blog post and waiting for you to notice somehow—this communication structure that we’re using here is very useful to us, even if I can almost guarantee that this post is going to be flattened into a massive paragraph by micro.blog. No problemo—I’m just glad to have a direct line to you, Joe!)
Regarding another thing Kicks asked about: Aside from evolving html, accessibility, and design standards and practices, I’m really not sure if linking, in general, has changed over the years. I’ve been doing it the same since day one. But that’s just me.
For me, I do find that Webmentions are really enhancing linking—by offering a type of bidirectional hyperlink. I think if they could see widespread use, we’d see a Renaissance of blogging on the Web. Webmentions are just so versatile—you can use them to commment, you an form ad-hoc directories with them, you can identify yourself to a wider community. I really feel like they are a useful modernization.
But I like that you are true to the linking you’ve always done. It still works. It’s an ideal that we fell away from I guess.
The Third Policeman, of course! But also: Heartsnatcher by Boris Vian (just my kind of meandering, vexing thing), Writers by Antoine Volodine. And soon I will get into Impressions of Africa by Raymond Roussel. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Hate to say this, brother—but I actually think I follow your diagram, hahah—I mean what can I say, it’s terribly complex, but sometimes these things have to be. Yeah and like you say: Rube Goldberg. I say go for the madcap every time. If I tried to diagram my structure in dashes-and-pipes, it’d be like that, too, actually. Ten layers of tooling. Salud.
You seem quite good at stepping back and asking what the hell you’re doing. I’m going to keep a close eye on all of this, because I think the moment will come when we can bridge Indieweb and your world. It actually won’t offer you much—I think it’ll just automatic copy-and-paste is all. Depends on your feelings about syndication—seems like we both have complicated feelings about RSS. Which, to me, makes it a ripe topic.
As I have tried to say to both of you, I’m very interested in hardcoding my links. I want hardlinks statically sitting in a tiddler rather than some filterlist rendering upon opening a tiddler. The recursion problem is so serious for javascript that it cannot be performant enough to enable me to rely upon anything other than significant hardlinking. I think Bob may be the key to enabling hardcoding in a way that I can do.
Oh, I agree with you—I do the same thing on my site. I don’t ever use a query (filterlist)—I always hardcode links. It’s too important to lay it out right. It also forces me to limit the amount of meta-pages I have. I think they have to be used judiciously because people aren’t going to wade through a whole lot of meta. Those kind of automatic pages always lead to bland, repetitive layouts.
It’s evident that you hand-build your pages and they are 10x more appealing as a result (e.g. your link logs are ace).
My goal is to construct a signed wiki (and snapshots) that I can distribute however I need. I desperately aim not to centralize the distribution process any more than is necessary or reasonable low-hanging fruit (perhaps that will change). The fact is that I want to tie this wiki to my commandline to accomplish certain tasks, and that means Bob is absolutely critical (for keeping it real-time). I still want to produce a single html file to maintain whatever distribution model I see fit, but that is very doable for me now, I believe.
This is sweet—I am trying to do a lot of the same things. In fact, I’ve just got things working so that I can post from different machines at last. I’m going to end up very close to the top-half of your diagram: all my posts and layouts get checked in to Git, but I still need to do a bit of work on my outputs to Dat and single-file HTML.
You have any other pointed questions—weak points you’re worried about?
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Looks like your theme is probably compatible—hard to say until you install and we try some posts back and forth. I don’t know Wordpress at all, but I can help fix the theme up. It honestly looks really close, so it should just be minor tweaks. The theme is definitely too good to lose.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Hi, Neil—good to hear from you.
Can you expand on what you mean? It seems like you’re suggesting that maybe IRL simply is the domain for the personal? Maybe hypertext (or perhaps VR and such) will never quite be that place. Or am I misreading?
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Oh and yeah—can you pass along this link trove? I do a monthly ‘href hunt’, asking everyone out there for personal URLs—one of the problems is where to go to notify the world of one’s nascent blog or wiki? I can write up your collection—or link your write-up. Anything to help.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A self-catalog—tho this format could fly as an outgoing directory.
I mostly cover obscure writers. James is a widely published author (The Atlantic, Playboy, Aeon) but this is a neat personal directory to his writing—very homespun and lightly annotated, with asterisks and highlighting used to nice effect.
Articles such as How I Reverse Engineered Google Docs To Play Back Any Document’s Keystrokes are a festive hybrid of code, anecdote and sundry links—found in paragraphs festooned with blue underlines that act like surprising miniature directories nested in the article. (This is an approach that I feel I need to cover in Foundations of a Tiny Directory.)
I also think it’s interesting that he catalogs all of his individual blog entries. This whole page very much fits in with my definition of Hypertexting—these scattered essays and posts become a body of work here. And the quality is excellent: generally well-considered and well-executed.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Some essentials.
This is my first ‘person’ page. And, of course, h0p3 has been doing this for a very long time and I am only copycatting. His are ‘light-hearted plain-web d0xxings’ or somesuch—email, address, phone number, links to conversations. Mine are just that person’s words and my thoughts in summation—which is far more of a calling card to me, particularly after these other identifiers have expired.
As with most things, though, I am still playing catch-up with him. (He is the premiere modern Public Self-Modeler, in an age where such a thing is possibly dangerous, uncomely and, well, selfie-stickish.
He says in Find the Others:
I believe that by honestly uploading my mind into my wiki, we both have access to an enriched network of references for generating accurate theories of each other’s minds.
Ahh, dear me, so then it takes much more than a page—this entire endeavor is sunk. There can be no eulogy or summation. It would take a massively overloaded TiddlyWiki to accurately describe such an one as this…
To some non-trivial extent, the labels, attributes, characteristics, properties, and models I generate about a person help form a kind of name.
In reply to this, our friend Sphygmus[1] writes:
I want to talk about the vocabulary of “modeling” another person as well. I think I have observed that people don’t understand what you mean when you say you clearnet doxx them in order to better model them. For me, though, that was one of the most intuitive things you say. When I was in college the first time, I worked as an ILL student worker and loved it, largely because it sent me wandering through the stacks to pull out such a varied selection of books. One of the books I pulled that really stuck with me discussed how we form mental models of people in our heads and rehearse conversations with those people at various times, and the ways in which those rehearsals could be helpful or not. If I remember correctly, there were even worksheet-like questions for shaping mentally rehearsed conversations in a more helpful way. Sadly, I can remember exactly where I pulled the book from in the library but I’ve been unable to figure out the title – I wish I could go back and read it again!
Of course it also has to do with the problem of other minds and the unbridgeable gap between me and the outside world. Inevitably we only know others through our construction of them within our own minds.
After a discussion of the merits of psychometric tests between the two, h0p3 says:
I am inevitably forced to use labels, adjectives, etc. to model (boxing things in is what makes it computable information at all for us).
Ah, well—so this page is my box. And these are the things I put it in it.
(If you meet someone—someone with ASCII glasses on, say—and they purport to be a ‘madman in the desert’—then put this page straight away. FOR YOU NOW have the genuine artifact in front of you!)
(However, if you are uncertain, you can do one more thing: you can tell the man a joke. Like: a homunculus and a dark triadic memetic walk into a bar. He will stop you. ‘Let me stop you right there. Before you finish, please know that I am quite literally autistic and your elegant form of advanced humor which you are so carefully deploying might end up lost in my limbic system somewhere. Forgive me, please, and tell your joke, and thank you for saying it is a joke—k0sh3k will laugh at me later for this, but I will test out three interpretations of the joke with you now and then have her review the transcripts later…’)
(These overwhelming feelings of endearment and admiration and sheer pity that are now coming over you will now materialize in the form of laughter. The joke that was designed to pique the curiosity has now been outpiqued by a new curiosity: one in ASCII glasses that has gone to such great extent to analyze the joke that has been placed on the table—and, now look—this analysis has expanded everything in sight. You look at the joke and see that it is much bigger. And the conversation is now expanded, it is bigger. And the table—the table is much bigger, too!)
(Ok, now, tell me: did you laugh? Did you feel some endearment and admiration and some pity? I don’t know if you will enjoy or love h0p3 as much as I do, or as much as I purport to—if not, well, then I understand that, too. There was a time when I thought that I would only frustrate him or that he might just annoy me—I was reluctant to say anything or to take the time to read so very many words…)
(But what is life but a chance to expand a joke, to make the conversation a little longer, or to fancy that maybe even the table at which we sit has now grown?)
I aim to do you justice.
It’s that chivalrous, sensible, steelnivorous h0p3—he steels you up, then it’s all night steel for breakfast!
This short sentence is a trope of h0p3. He ‘aims’—he has a very specific set of purposes in mind for you, good good, his work is a pointed effort. A discovery of truth? A deep sea recovery of some rarified moral sense? I cannot characterize it properly. But to ‘aim’ is truly a bold facet.
True literature can exist only where it is produced by madmen, hermits, heretics, visionaries, rebels, and sceptics.
— Yevgeny Zamyatin
The world is kept alive only by heretics: the heretic Christ, the heretic Copernicus, the heretic Tolstoy. Our symbol of faith is heresy.
— Yevgeny Zamyatin
That h0p3 labels himself a ‘madman’, a ‘jester’, a ‘retard’ and so on—well, this is a rich tradition and these are rarified, very colorful and storied appellations. I do think of Zamyatin—who is forgotten to our society, but who was prescient to the disasters of the 20th Century that he lived in. We was a catalyst to the entire utopian and dystopian genres. (I have no doubt that my beloved Vigoleis also saw himself among this rabble.)
This is cause for alarm—and I see this in h0p3’s more dismayed dispatches from time to time—the world will not be kind to him. However, he is a heretic—we know this. He must do his work; it is too valuable.
I am wet with paranoid anticipation.
Sweating. Strange. Eager. A fork. I imagine him holding a fork. A big fork for grilling? No, a regular fork. Persperating. Eyes a-poppin. Veiny eyes. Saucer veiny eyes. Really sweet, sweet, shiny fingernails, right? Very eager. Heyooo!
Oh, wait. Wet, hahaha, forgot the best part, yeah, wet-t-t-t!
I’m trying to decide whether this codes as just IAWWPA or something more like just being ‘parawet’. THIS IS VALID HONEST WORK.
A friend. What more do you need to know? ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Man oh man! This is a great honor. I really feel humbled by this—you are already gifted at the work I aspire to do—and I intend to develop the essay further based on what I see at Linkport.
For example, I would really be interested in any further advice you have for someone who wants to linkblog or start a directory. Beyond an essay, it would be interesting to take a stab at a ‘guide’ for hyperlinkers. I am very grateful that you took the time to read, Joe. (I think this natural—a noble attribute of a hyperlinker is the capacity to care about others and what they are doing—to be intrigued by them is to move from just caring about what they are doing toward fascination. Perhaps crossing that line is where a link to someone begins.)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I’m sorry to worry you—there are just too many things in life that pull me away, so this will happen sometimes. I really appreciate your concern, though. I feel a friendship with you and I am following EVERYTHING you’re doing on Indieseek. (I am really pouring time into the directory so that I can keep pace with you and link back-and-forth there.)
It will be interesting to see if I can accomplish the work we’re striving for without being connected every day…
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This article is in my dept, man—great stuff. I am writing a blog that covers obscure websites, interviews unknowns, etc. Although I am advocating a return to (dun dun) web directories: https://www.kickscondor.com/foundations-of-a-tiny-directory
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
More thoughts on moving beyond Google.
I’ve been saying for awhile that Google doesn’t work for me—but I think this essay crystalizes the thought in a much better way than I’ve been able to.
If you click through all 14 pages of results Google returns for [disney], nothing I could conceive of as interesting appears. Corporate website this, chewing-gum news article that. But if you refine it a little and search for [disney blog], then by result Page 7 things start to get interesting.
I’m not sure I agree yet with the idea that we can solve this with better search engines—I am really focused on trying to bring humans back in: as editors, as librarians, as explorers—we can do this kind of stuff really well, this is our strength! But I’m warming up to the idea that search engines could be a tool for these surfers.
What is clear to me is that it is time for separate tools. A search engine designed to be used by billions of people every day to do daily tasks is not one that will be appropriate for weekend meanderings though obscure topics. A content-sharing site like Reddit that encourages links to the New York Times will not generate thoughtful discussion.
See, to me the issue is that ANY algorithm involves encoding a ruleset that strictly describes what it is looking for. So by the time you encode your crate-digging behavior as an algorithm—it has lost its flavor.
Imagine a computer writing jokes. Not that that can’t work—but I think computers are far away from making jokes that aren’t inadvertant. So only by being nearly random does it become evasive enough to avoid malignant behavior. But a human is subject to its own evasive manuevers—it can get fatigued with sameness, it can become bored, it can become sensitive to the fashions of its time, it has its own ineffable subjectiveness. So it is capable of leaving its encoding—of evolving, or of returning to its roots, discovering something forgotten or uniquely nostalgic. (I think the algorithms are great for discovering the answer to a technical question—you want that search to be predictable.)
This is a great article and it describes a longing for the kind of thing that we’re all trying to build here—I know it sounds like I’m wrapping all of you out there—and those I’m communicating with regularly—in a blanket statement—if I am, then certainly push back—but I think this is what ties us: to preserve humanity on the Web, perhaps to find more meaning in this work. So I hope to see this Crawshaw person around here at some point.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Been busy with a bit of travelling and working on my link directory, but have been reluctant to just post a pointless update such as this one—senselessly notifying everyone. However, aren’t pointless things terrifically human?? It seems that to post a note like this stumps and defies the algorithms and is emblematic of the struggle this blog is making (and its friends) to preserve humanity in hypertext. I think that if I fall into a pattern of just littering the world with tech tutorials and link discoveries (as if it were ‘breaking news’) then I am losing out on the human chance to thank you for reading or talking to me and to say something meandering or listless, which is eminently human and could help to shake your automated daily ‘feeding’ out of the rigor of new tutorials, new news and remind us that we are both typing and flicking cursors around and somehow smiling at each other through it or pondering each other in confused or amused reveries—I think ‘weird twitter’ was able to accomplish this, but I wonder if one can only make technology human by completely subverting it—these reveries are happening, but they are not synchronized and it happens with great distance between us in many dimensions. I enjoy it a great deal, though, and hopefully you do, too.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Fleshing out a footnote in the spacing between parts eight and nine of my reply.
Ok—this is a great angle I haven’t approached yet. Do I provide a dark whostyle? Does it get computed from the actual whostyle? Could there be several variants offered?
I also think it’s really cool that you ended up just baking your own style that feels like me to you. Hey, yeah, go with that.
Well, if someone redesigns—might they still want to give people out there a choice between the old and the new? I think there is no need to overdesign this. I think you could just offer multiple whostyles. The hard part, for me, is to concoct a dark style from what I have—but this excites me, I’m on it.
If you have a secondary mildly-darker background I can use, I will use that. I hate that the solution to my light sensitivity detracts from your intentional style.
Yeah, it’s not practical for me to make custom styles for every user of my website—perhaps that’s where your troubled feelings arise. But fuck practicality! I will gladly make a custom style for anyone out there. If you care enough to read, then I would like to care enough to make things comfortable to you.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Wow, you hand-check the whole thing?? Ok, wow, so if you don’t mind I have a few more questions—actually, quite a few more, but I’ll constrain myself!
Also, if you’d rather post your answers as a blog post, I can link to that. Great to meet you—I’m immediately a huge fan!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Hot takes aside, I thought Universe was a pretty neat tool when I last looked at it. These kinds of things can have really poor money strategies and still have novel ideas inside.
So, yeah, I thought the editor was a nice, simple tool for building little web pages with blocks of text and pictures. I’m planning to use it for a project at the elementary school to see how the kids use it. (This seems like the rare technology that has enough color and expressiveness to be useful to me there—especially now that Byte is defunct.)
If we can learn from the good tools, they can help us figure out how to craft the Indieweb. We will need more than just protocols.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Cool thread. Getting myself in here. Hi, folks!
Joe, amazing site—Linkport. How on earth have you kept the links all intact? I couldn’t seem to find a broken one.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Joe Jenett’s link collection—been going strong for decades.
Oh boy, the micro.blog surf club is really coming together: Joe Jenett has said ‘hello’ by dropping a link to this directory of fantastic obscure blogs and things. (I think he and Brad Enslen met through Pinbard? Does that happen??)
Linkport goes back to 2000. But Joe has been collecting links since 1997:
I thought of pulling the plug (on the daily pointers) for the same reasons but decided to keep it going with a combination of new links and repeat links to sites with recent updates, along with working hard to keep it clean of bad links. Yes, it all takes a lot of time but fortunately, I enjoy doing it - it’s in my blood.
Even the oldest links in the directory still seem to work. I bow in humble deference.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Part one of thirty-five.
Sweet letter—I’m going to dig into this further over the next while, I’m going not to say much here, because h0p3 has many things to do and I don’t want there to be any timer started just yet, in fact, let’s suppose that I’ve already written a very lengthy reply, but am just sitting on it, to let the wide variety of worthwhile non-hyperconversation things transpire. Just want to mop a few fallen fruits off the floor.
TW defeats a number of frictions like a champion. I posit that TW is radically more decentralization-capable than Dat. Legions of analog and digital systems can move one file, but it is possible only few will speak Dat.
Oh, for sure—its resilience is proven. I side with TiddlyWiki in the long-term, no doubt. In fact, I am siding with its powers of adaptation. It runs on Node, it runs on Beaker—let’s push that adaptation further. (Perhaps this means that Dat is less resilient and will fall—but I think the protocol has to be narrow/simple to see widespread use.)
My money is on WASM-Web 3.0 taking further down that rabbithole.
I’m great with this, so long as we don’t lose hypertext in the process.
To my eyes, Dat is competing with IPFS, Syncthing, Resilio Sync, mutable torrents, etc. For now, I just use Resilio Sync for the functional Dat-properties I need.
Try to keep in mind that it’s not even Dat that excites me about Beaker. It’s that you can read-write entire locally synced folders from the same languages ‘for which every computer has a virtual machine’. With Beaker, I can make an editable copy of your wiki—even if it was split into tiddlers, even if it was in a thousand pieces.
This is clearly an innovation that we follow. Take the rock-solid v.machine and let it create, babe.
I’m a P2P idealist who agrees there are classes of problems which can only efficiently be federated.
Mmmm, yes—same here. One of my fave networks was Soulseek. You could connect to people and see all the files they were sharing. I ended up just raiding people’s shelves rather than trying to track down Pavement b-sides. But that required some kind of cohesive network where you can ‘see’ everyone.
Wowowow-it’s still there! Just installed. There is a lot of good stuff still on here. How has it stayed so obscure and devout?
A starting place for the opposite style seems like poetry or crystallized summation. It only shows semblances, outlines, glimpses, fragments, and impressions on purpose. I think it must be antipleonasmic.
Yeah, this is a sweet letter. I hope there’s a worthy reply somewhere in my timeline.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
It’s more common to converse with a computer than to just dictate our instructions to it.
I’ve been helping a friend with a Discord bot, which has opened my eyes to the explosion of chatbots in recent years. Yes, there are the really lame chatbots, usually AI-driven—I searched for “lame chatbots” and was guided to chatbot.fail, but there’s also the spoof ‘Erwin’s Grumpy Cat’ on eeerik.com.

We’ve also quietly seen widespread use of sweet IRC-style bots, such as Slack or Twitch or Discord bots. These act like incredibly niche search engines, in a way. My friend’s own bot is for a game—looking up stats, storing screenshots, sifting through game logs and such.
So, yeah, we are using a lot of ‘one-line languages’—you can use words like ‘queries’ or ‘commands’ or whatever—but search terms aren’t really a command and something called a ‘query’ can be much more than a single line—think of ‘advanced search’ pages that provide all kinds of buttons and boxes.
Almost everything has a one-line language of some kind:
Humans push the limits of these simple tools—think of hashtags, which added categorical querying to otherwise bland search engines. Or @-mentions, which allow user queries on top of that. (Similar to early-Web words, such as ‘warez’ and ‘pr0n’ that allowed queries to circumvent filtering for a time.)
It’s very interesting to me that misspellings and symbolic characters became a source of innovation in the limited world of one-liners. (Perhaps similar to micro.blog’s use of tagmoji.)
It seems that these ‘languages’ are designed to approach the material—the text, the tags, the animated GIFs—in the most succinct way.
I wonder, though, if ‘search’ is the most impotent form of the one-liner. It’s clearly the most accessible on the surface: it has no ‘commands’, you just run a few searches and figure out which ‘commands’ work until they succeed. (If they do?)
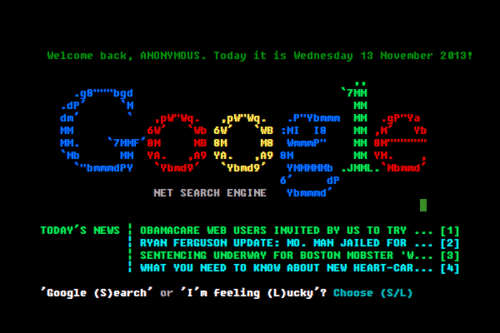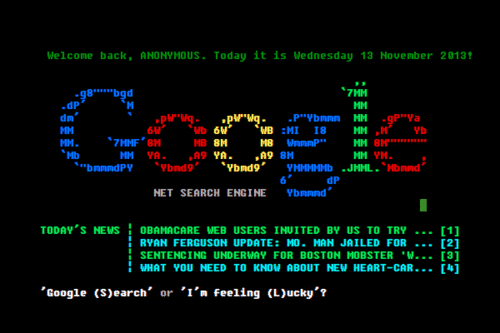
It also seems relevant that less than 1% of Google traffic uses the I’m Feeling Lucky button. Is this an indication that people are happy to have the raw data? Is it mistrust? Is this just a desire to just have more? Well, yeah, that’s for sure. We seem to make the trade of options over time.[1]
Observations:
Some sites—such as yubnub and goosh—play with this, as do most browsers, which let you add various shortcut prefixes.
Oh, one other MAJOR point about chatbots—there is definitely something performative about using a chatbot. Using a Discord chatbot is a helluva lot more fun than using Google. And part of it is that people are often doing it together—idly pulling up conversation pieces and surprising bot responses.
Part of the lameness of chatbots isn’t just the AI. I think it’s also being alone with the bot. It feels pointless.
I think that’s why we tend to anthropomorphize the ‘one-line language’ once we’re using it as a group—it is a medium between us at that point and I think we want to identify it as another being in the group. (Even in chats, like Minecraft, where responses don’t come from a particular name—the voice of the response has an omniscience and a memory.)
It’s also amusing that Google keeps the button—despite the fact that it apparently loses them money. Another related footnote: the variations on I’m Feeling Lucky that Google has had in the past. Almost like a directory attached to a search. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
My ‘whostyles’ draft—a proposal for styling hypertext that gets quoted or syndicated outside of your site—is here.
My ‘whostyles’ draft—a proposal for styling hypertext that gets quoted or syndicated outside of your site—is here.
Further notes on development will go here.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A directory of ‘federated’ communities.
A list of all of the various blogging and messaging services that are connected to each other by way of ‘federation’ (e.g. Mastodon). This is impressive—user statistics and lists of smaller communities within each group. I’ve thought that the Indieweb was ‘ahead’ of the Fediverse, but it’s much easier to find each other with this kind of centralized directory.
I also generally advocate human-curated directories. But, in the case of examining the offerings of a network, this kind of entirely machine-constructed catalog makes perfect sense. A stat-based and rather spreadsheet-like view is the whole point.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This also applies to the TiddlyWiki approach—by having the entire HTML in a single file, it also could be seen as ‘hermetically sealed’—tho secret JS and analytics could still be there (as they could with podcasts). I also wonder if this is the appeal of Reddit’s minimalist design.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I’m wondering if the rise of podcasts is a reaction to the threat of algorithms. Basically, since podcasts are binary audio files, algorithms currently can’t rewrite the thing—it acts as a hermetically sealed container containing humans talking.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Will your .pizza domain survive?
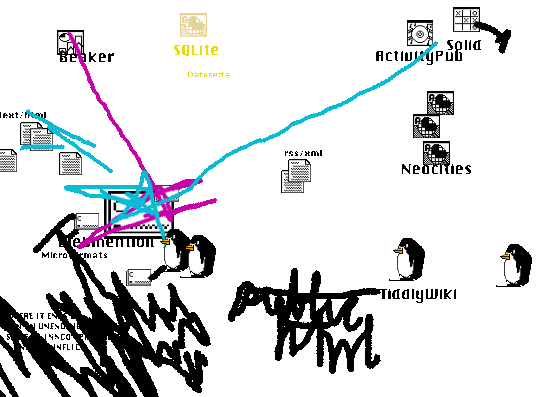
Beaker vs TiddlyWiki. ActivityPub against Webmentions. Plain HTML hates them all.
I step back and, man, all the burgeoning technology out there is at complete odds with the other! Let’s do a run down. I’m not just doing this to stir up your sensibilities. Part of it is that I am lost in all of this stuff and need to sort my socks.
(I realize I’m doing a lot of ‘versus’ stuff below—but I don’t mean to be critical or adversarial. The point is to examine the frictions.)
At face value, Beaker[1] is great for TiddlyWiki[2]: you can have this browser that can save to your computer directly—so you can read and write your wiki all day, kid! And it syncs, it syncs.
No, it doesn’t let you write from different places yet—so you can’t really use it—but hopefully I’ll have to come back and change these words soon enough—it’s almost there?

Big problem, though: Beaker (Dat[3]) doesn’t store differences. And TiddlyWiki is one big file. So every time you save, it keeps the old one saved and the network starts to fill with these old copies. And you can easily have a 10 meg wiki—you get a hundred days of edits under your belt and you’ve created some trouble for yourself.
Beaker is great for your basic blog or smattering of pages. It remains to be seen how this would be solved: differencing? Breaking up TiddlyWiki? Storing in JSON? Or do I just regenerate a new hash, a new Dat every time I publish? And use the hostname rather than the hash. I don’t know if that messes with the whole thing too much.
Where I Lean: I think I side with Beaker here. TiddlyWiki is made for browsers that haven’t focused on writing. But if it could be tailored to Beaker—to save in individual files—a Dat website already acts like a giant file, like a ZIP file. And I think it makes more sense to keep these files together inside a Dat rather than using HTML as the filesystem.
While we’re here, I’ve been dabbling with Datasette[4] as a possible inductee into the tultywits and I could see more sites being done this way. A mutation of Datasette that appeals to me is: a static HTML site that stores all its data in a single file database—the incomparable SQLite.
I could see this blog done out like that: I access the database from Beaker and add posts. Then it gets synced to you and the site just loads everything straight from your synced database, stored in that single file.
But yeah: single file, gets bigger and bigger. (Interesting that TorrentNet is a network built on BitTorrent and SQLite.) I know Dat (Hypercore) deals in chunks. Are chunks updated individually or is the whole file replaced? I just can’t find it.
Where I Lean: I don’t know yet! Need to find a good database to use inside a ‘dat’ and which functions well with Beaker (today).
Ok, talk about hot friction—Beaker sites require no server, so the dream is to package your raw posts with your site and use JavaScript to display it all. This prevents you from having HTML copies of things everywhere—you update a post and your index.html gets updated, tag pages get updated, monthly archives, etc.
And TiddlyWiki is all JavaScript. Internal dynamism vs Indieweb’s external dynamism.

But the Indieweb craves static HTML—full of microformats. There’s just no other way about it.
Where I Lean: This is tough! If I want to participate in the Indieweb, I need static HTML. So I think I will output minimal HTML for all the posts and the home page. The rest can be JavaScript. So—not too bad?
ActivityPub seems to want everything to be dynamic. I saw this comment by one of the main Mastodon developers:
I do not plan on supporting Atom feeds that don’t have Webfinger and Salmon (i.e. non-interactive, non-user feeds.)
This seems like a devotion to ‘social’, right?
I’ve been wrestling with trying to get this blog hooked up to Mastodon—just out of curiosity. But I gave up. What’s the point? Anyone can use a web browser to get here. Well, yeah, I would like to communicate with everyone using their chosen home base.
ActivityPub and Beaker are almost diametrically opposed it seems.
Where I Lean: Retreat from ActivityPub. I am hard-staked to Static: the Gathering. (‘Bridgy Fed’[5] is a possible answer—but subscribing to @[email protected] doesn’t seem to work quite yet.)

It feels like ActivityPub is pushing itself further away with such an immense protocol. Maybe it’s like Andre Staltz recently told me about Secure Scuttlebutt:
[…] ideally we want SSB to be a decentralized invite-only networks, so that someone has to pull you into their social circles, or you pull in others into yours. It has upsides and downsides, but we think it more naturally corresponds to relationships outside tech.
Ok, so, perhaps building so-called ‘walled gardens’—Andre says, “isolated islands of SSB networks”—is just the modern order. (Secure Scuttlebutt is furthered obscured by simply not being accessible through any web browser I know of; there are mobile apps.)
This feels more like a head-to-head, except that ‘Bridgy Fed’[5:1] is working to connect the two. These two both are:
I think the funny thing here goes back to ‘Fed Bridgy’: the Indieweb/Webmention crowd is really making an effort to bridge the protocols. This is very amusing to me because the Webmention can be entirely described in a few paragraphs—so why are we using anything else at this point?
But the Webmention crowd now seems to have enough time on its hands that it’s now connecting Twitter, Github, anonymous comments, Mastodon, micro.blog to its lingua franca. So what I don’t understand is—why not just speak French? ActivityPub falls back to OStatus. What gives?
Beaker Browser. A decentralized Web browser. You share your website on the network and everyone can seed it. ↩︎
TiddlyWiki. A wiki that is a single HTML page. It can be edited in Firefox and Google, then saved back to a single file. ↩︎
Beaker uses the Dat protocol rather than the Web (HTTP). A ‘dat’ is simply a zip file of your website than can be shared and that keeps its file history around. ↩︎
Datasette. If you have a database of data you want to share, Datasette will automatically generate a website for it. ↩︎
fed.brid.gy. A site for replying to Mastodon from your Indieweb site. ↩︎ ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I’ve been behind on posting these: HrefHunt for the month.
This is my directory of folks out there that I meet or who contact me. (Pssst, Let Me Link to You!)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A religious satire crossed with a home page. This is also covered in this episode of a show called Deep Web Browsing. Just linking this in case I want to follow the trail further.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Indices, catalogs and maps of the hypertext ‘body’.
I am discovering more and more of these—what I am calling ‘link maps’, perhaps there is another name—collections of links that act like an index or a topical guide to a large ‘body’ produced by Hypertexting. You might want to conflate these with wikis—most wikis do act like ‘link maps’—but I am specifically looking at a ‘link map’ and a ‘body’ as being seperate entities. Much like a map and the dungeon or landscape that it maps are separate.
A very similar word is ‘sitemap’—perhaps ‘external sitemap’ is a better term—but I tend to think of a ‘sitemap’ as a complete map, whereas a link map might be limited or contain duplicates (like an index). (For comparison, see the sitemap for Purdue’s writing guidelines or the SuperMemo sitemap as standard examples. Though, I’m not sure how these would differ from a ‘table of contents’. Or a ‘home page’—such as Paul Burgess’ home page, which is a directory to itself.)
Some of my collection:
The Mother Horse Eyes index, which maps the stories, background, chronology created by Reddit user _9MOTHER9HORSE9EYES9. (Reddit wikis do function more like ‘link maps’ usually, because they are attached to an arbitrarily-shaped body of discussion.)
The story index for Alice and Kev, the story of being homeless in The Sims 3. This one interests me because it is a completed blog that has been organized by the writer.
The Mencius Moldbug topical archive and chronology. Please don’t make me comment on what ‘toxic’ or ‘enlightened’ substance might be in these papers—I have no idea. I am just looking at the layout and possible uses of the link map. (Related: Yvain’s posts on Less Wrong.)
Index of users banned from the ‘slate star codex’ reddit.
QAnon Map, it’s crazy to me this polished, almost military-grade skin over a 4Chan. I think this is sufficient proof that the underlying technology doesn’t matter—and it may even be a benefit to be plain, easy to copy-paste—when building a hypertext ‘body’.
_why’s Estate, collected writings of a programmer who abandoned all of his work.
Gwern’s home page is a topical guide to the site.
These all seem to follow the collapse or completion of a work—very few maps seem to be made while the ‘body’ is underway. I also wonder to what degree these misrepresent the ‘body’.
This document, however, isn’t a ‘link map’ because I am just linking to a bunch of separate ‘maps’ rather than focusing my links on a single ‘body’ of work.
I will add to this list over time, who knows where it’s going.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A+ commotion in the background.
Found this under the dank tag—a rambunctious nexus into an underworld of ‘shitty’/‘dank’/‘great’ games. Quite a lot of Easter eggs in there. (Click on the warp tube.)
For more by Nathalie Lawhead, see alienmelon and unicornycopia. This feels like the same department as Cactus or the music on that one wedding page.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I spent about a week playing with Federated Wiki and was initially extremely excited about it—I’ve always admired Ward Cunningham’s work, there was a recent blog post called The Garden and the Stream that promoted Fed Wiki as a way to do Hypertexting (‘the garden’) and I had hoped to integrate my hypertext with it.
However, it simply did not function for me and I could not seem to find useful protocol documents. I didn’t even feel like it was worth posting about yet. I will continue to keep an eye on it to see if it becomes something practical. (Even as a reader, I find fedwiki.org really neat but difficult to use—I feel that it is more opaque than TiddlyWiki even.)
If you chose to go with a search feature, I was going to add you to the search engines at the bottom of Indieseek’s SERP like I did with Wiby.me. That way I could share traffic – like someday when I have traffic, with your directory.
Yeah, so—I think we start talking about federating our directories. Here are some basic starting points:
A central search engine that we can use to index our directories. I will work on this at some point. Or maybe sites like Wiby.me could collaborate with us. I may require microformats for the directory entries and maybe there will be a novel way to use Webmentions.
And, possibly, a directory using the same index—the question is how to find matches between our categorization systems. Perhaps we could treat categories like tags—or to provide a mapping to another category system.
Perhaps a way of collecting submissions from a central bucket? Maybe we could publish our submissions on a page, regardless of whether they’re included—this could also be useful for establishing a spam list.
It would be cool to syndicate entries—like I may want to take an entry from yours and embed it in mine. People may want to syndicate entries elsewhere—maybe as Twitter cards. And, most importantly, I may want to periodically ‘guest’ a directory and highlight that directory’s activity for a month.
I think it’s also useful to acknowledge that this is all different from Pinboard because our directories:
Are heavily filtered. We don’t include stuff that is ‘to-be-read’ or not (in our view at least) of very high quality or interest.
Entries generally have thorough commentary.
There is kind of a team thing going on—you and I are working separately, but there is a lot of collaboration and linking going on—I see this being good long-term because we can rope in others who cover other topics and act like a decentralized DMOZ. We could even safely double-up on the same topics because people will have different takes.
Interesting point about using comments and stars yourself. Sounds cool!
I will definitely add a query string search and will look at doing what you do on your results page. Cool, so far, so good.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I didn’t much care about search when you said this, but using h0p3’s search and your directory and Pinboard—there’s no doubt that it’s useful. It warps you to a place in the collection that’s workable.
I’ve worked out a search index that’s entirely done in JavaScript—it’s the same one I’m now using on my blog. Thanks to TiddlyWiki for helping me realize that this could be a great way forward!
When I publish, it updates the search index. (Right now my blog’s search index is 300k. Raw text of my blog is 1.2 megs. The index is loaded when a search is performed and cached for further searches.) I haven’t decided where to place it in the directory yet.
In 20 years I’ll either be dead or so old I won’t care. My time horizon is a good 10 years, which is forever in Internet time and is part of why I’m doing this now rather than dithering. You are right this is a long term game.
Hah! I laughed when you wrote this and I might as well voice it now. See you in
ten years, brother. 
This is all good. The Indieweb folks are taking care of the social aspect, which is blogcentric sorta by definition. We can aid in discovery for the blogs and the non-blog sites. If there is to be an Independent Web X.0 somebody has to help map it.
I think one of my primary questions these days is: will the future be blogcentric? I feel like things are going to change. Although they could get more hyperactive. Thought streaming? Let’s hope not.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Normally I wouldn’t link to a large magazine, but this is relevant to the ‘hypertexting’ discussion.
My friend Nate first told me about this fellow—Karl Ove Knausgaard—who has become a substantial literary figure, which would normally qualify him to be ignored by me. Surely he has enough attention, what with every major magazine taking time out to heap praise on his work. Which bears striking similarity to h0p3’s wiki[1] and to my definition of Hypertexting—the creation of a massive ‘body’ of text, often as an avatar for one’s self. (I, too, am building a ‘body’ but I’m not sure that it’s of myself. No indictment to ‘self’ intended.)
Knausgaard’s six-volume My Struggle has concluded and so folks are internalizing it. In the book, the author attempts to lay bare every particle of his mind, life, relationships and—where do I stop?—it’s an autobiographical work that purports to leave nothing private (nothing? I haven’t started the first volume yet) and, so far, Oprah Winfrey hasn’t made him take anything back.
In violating prevailing standards of appropriate personal disclosure, “this novel has hurt everyone around me, it has hurt me, and in a few years, when they are old enough to read it, it will hurt my children,” he writes. “It has been an experiment,” he continues, "and it has failed because I have never even been close to saying what I really mean and describing what I have actually seen, but it is not valueless, at least not completely, for when describing the reality of an individual person, when attempting to be as honest as possible is considered immoral and scandalous, the force of the social dimension is visible and also the way it regulates and controls individuals.
I don’t know if this article is hyperbolizing the whole thing or what—I read around some other thoughts on the series and found other similar reactions.
From Literary Fundamentalism Forever:
At the end, in the last line, he says he’s no longer a writer, something he’s since disproven. But there’s something about this that’s like he’s put it all out, eviscerated himself and stretched the entrails out like Keroauc’s unfurled scroll along a shuffleboard table. He’s exhausted his capacities. And I’m sure that’s something that many writers have wanted to do at one point but never come close to achieving.
I’ve (and we’ve) been very busy having the meta-discussion about writing and cataloguing and relentless thought collection—we have kinship with this guy’s work. It might be that everyone is dealing with this, with the rise of an ‘automatic’ writing culture all around. I think the interesting thing that Knausguard offers is the moment of a ‘completion’. His six-volumes are up, but his life isn’t—and he’s gone on to write a four book cycle.
So, homework:
When can a ‘body’ be called done—what are the utilities of this moment, how do you see it coming?
For my own sake, I wonder how I might foment a reaction to the logorrheic approach that offers restraint—my Tuesdays and Fridays, for one—although I still end up feeling thoroughly logorrheic and I think I do exhaust anyone passing through. But: I feel to question this approach (hardly to demonize it) but what could a Reverse Knausguard ‘body’ style itself as?
What does the non-linear hypertext bring to the table?
For some reason, this work does help me really enjoy modern times.
Surely by now you know the link. And, anyway, after yesterday’s discussion of hypertext ‘entry points’, I’m not even sure how to appropriately link to h0p3. Go make your own doorway. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Cool—I am working on consolidating my bookmarks into a single directory (much like Brad has done at Indieseek.xyz, but it’s interesting to see you go with the approach of keeping links housed differently based on their purpose. It’s cool and your very thorough explanation is convincing!
I do like when people use Pinboard—and might consider double-posting there—mostly because I love that I can browse pinboard.com/t:toread to find interesting things. I keep looking for a common tag that means: ‘I don’t know what to think about this link.’
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
‘I didn’t really see it as being about anything…’
Man, I try to do interviews, but this is really good!
OL: Why and why in Heartland neighborhoods?
SS: Well, when I was thinking about putting a page on GeoCities there were various neighborhoods that were about specific things, and I didn’t really see it as being about anything, And Heartland seemed like sort of a friendly catch-all one, they called it the family neighborhood I think. So that seemed the best place for me.
I think there’s a temptation to call it ‘about nothing’ if it’s a page that’s not ‘about anything’. I love finding pages that just meander with no particular aim. Though it’s harder to name pages that are like that in the present.
OL: Let’s go though your home page. When I saw it for the first time it immediately attracted my attention, because you stroked through the Welcome to My Home Page
Welcome to My PageHere’s the Page
In the next sentence you explained that you strike it through because
“One of the books I looked at on how to code HTML said “Don’t put ‘Welcome to my page’ on your page”, because people already know they’re welcome, so I tried to think how to start this without putting that on first, and really, it seems sort of stark without some kind of greeting. So my second idea was just to say “Here’s the page”, as an homage to my seven-year-old son, who has started saying “Bon appetit” at mealtimes, and I discovered that he thought it meant “Here’s the food.”
This is such a sweet thing—and it reminds me that this sort of thing is still alive when people share the things kids say or fragments of overheard conversation and there is no stigma around those things. But I think there was some backlash against LiveJournal and the initial ‘meaningless’ Twitter status updates—but perhaps Susan was able to do this artfully. (I genuinely think her page is still great to read. It reminds me of a blog called Murrmurrs that I came across recently that I have been enjoying for similar reasons.)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A discussion of portals into a large hypertext.
Ok, this is rich—this point is on fire. We agree, yeah, oh hell yeah we agree. This is what I’m saying every third paragraph about how our technology is underutilized. This is a great example of the ‘social’ overemphasis of the single ‘post’ or ‘link’ or ‘article’ as opposed to the hypertext ‘body’.
(For anyone just joining this conversation, h0p3’s link in the quote above loads about 10 pieces of hypertext that represent his current ‘place’ in this massive [20 megabyte] ‘body’ he’s creating—so the ‘link’ he’s sent doesn’t represent a single ‘article’ or ‘tweet’, which is what we’re trained to think of a ‘link’ representing. And I wonder—beyond h0p3’s twenty megs—how can I ‘link’ to the ten related tabs I might have open so that you can see them together? How can you create your own ‘link’ that puts me into the center of a hypertext perspective you have?)
(In some ways, this reminds me of heavily cross-referenced and footnoted texts like religious scripture—which are hyperlinked in a fashion—and folks have long batched together references to these works through verse-chapter or page citations, and most often through quotes. The amazing feature of the link above is that it isn’t just a set of quotes—it is the definitive source material, connected to the live author. Is it possible that citation could be improved by allowing one to construct a link of views to many definitive hypertexts?)
I won’t even touch Reddit [and it’s spidering onto the rest of the web] without half a dozen tweaks and tools; it’s not worth my time.
I like to say that all our problems are human problems at this point—but I think I am starting to see that every site needs good search, some kind of indexing and a way of positioning it within the whole landscape outside of it. I wonder what tools you find most useful—are they just useful within Reddit or should they be available to you and I somehow?
I grant, however, that some methods are better than others. What counts as finding relevance in our hyperreading in general is some ridiculously hard problem. It’s probably fair to say most people will quickly run out of things they find worth reading on this wiki (if they found anything).
Yeah, I think if we start to get too ‘hyper’ we get lost in the linkage and things get blurry. I mean when it comes down to it, I just want to do some very basic things: meet people, connect thoughts, really dig into a concept, see neat things—and try to route around the armchair arrogance that seems to be plaguing the world.
I don’t plan to read your whole wiki—I plan to use it to research your takes as we correspond and to consult it while I’m studying, to see what other directions I can go. (I wonder if you’ll agree with this:) I think the point isn’t to make your wiki the Penn Station of philosophy—I just think some valuable things will bubble up out of your project that will connect to Penn Station bidirectionally. Just like I might draw from Vigoleis or Dr. Strangelove from time to time—philosopher.life is in there, too.
I’m not sure if I can say that they are manipulating the feed.
Manipulators treat the minds of others as mere means; they do not respect your dignity. Satya Nadella is a manipulator. Does that mean he and cabal of powerful deep state actors have conspired to control every little detail of your mind? No. But, the science of rhetoric, mass manipulation, and our ability as a species to produce increasingly effective apex predators only continues to rise. Power centralizes at any cost, including moral ones.
I guess I try to manipulate the feed, too, so yeah, of course he’s manipulating the feed. Why I’m reluctant to just pin the award on him: I’m not sure he’s actually accomplishing what he claims to be. I love that he’s put all of this work into influencing Hacker News, but his boasting about it could clearly undo all that work—so what kind of master manipulator are we really dealing with here?
The short-term efforts undermine the long-term—his infrastructure is not nearly as sound as it seems.
What are games except for sets of rules we play by to win?
Yeah, man, good questions. I think the trolls are way ahead in this effort—I think they see that they can create games that are honeypots. And I do think that the Internet still holds the power to flip the structure so that it is the powerful who get caught in these games that they think they can play. (Thus, the meme warfare centers.) I think the trouble is that trolls are chaotic and can align anyway they like—evil, neutral and good—are even ‘neutral’ and ‘good’ more likely to turn out to be ‘evil’ than vice versa? On the other hand, chaotics have been the Robin Hoods, the Guy Fawkeses, the Snowdens perhaps. I think we benefit by tapping into that subversive light-heartedness.
As you point out, we are still going to need a standard for when we define something as cooperating. If I respond to your letters with one word answers, I’m offering a token. You cannot escape measuring reality to some very large extent. I think this is part of our plight. Yet, the goal is to not be overly quantitative (where, unfortunately, “overly” is quantitative).
Oh—I like your arguments, answers and agreements on the T42T outlines. I think this also goes in with my thoughts on what I called ‘pluralism’ (but which really just means ‘a multimodal system of thinking’)—just as one needs to both ‘quantify’ and restrain from such a thing, just as one must respond in kind, respond with a token, respond with a tome (and never know precisely if one is doing it ‘right’)—it is always a constant balancing in a battle of extremes and competing ideals. Much like a relationship is a balance between what I am looking for and you are looking for.
So also I look at socialism and capitalism as arrows in my quiver; left and right as sides of myself more than two religions at war. This is overly simplistic—but so is T42T, it is a useful starting place for me. It is not the end, it is the curated entry point. It is the self-made doorway.
(The remainder of your letter—the part that essentially argues for staking a position—I am going to digest and figure out how to respond. I don’t have any problem with what you’re saying in a general sense; it is principled. I, personally, cannot get myself to ratchet down to anything concrete, for some reason. I think part of it is that I really do enjoy human beings—I am hard-staked against misanthropy—and that puts me in a really weird place wrt to modern culture and forming an alliance with a group rather than an individual. But if the mindset is totally bereft, then I am willing to abandon it.)
(As far as the TiddlyWiki loader: I am also waiting for more inspiration there. I think of that prototype as ‘chapter one’—I usually have to batch up ideas and code fragments in order to realize them. But glad it got the conversation going. I am thinking a lot about versioning—for example, can the timestamp also be part of the curated doorway that is the undercurrent of this exchange?)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
From the Microsoft quarterly earnings conference call:
Satya Nadella (head of Microsoft): In fact, this morning, I was reading a news article in Hacker News[1], which is a community where we have been working hard to make sure that Azure is growing in popularity and I was pleasantly surprised to see that we have made a lot of progress in some sense that at least basically said that we are neck to neck with Amazon when it comes to even lead developers as represented in that community. So we have more work to do, but we are making progress on all dimensions.
Yeah, that’s not mere ‘reading’. There is a sense of a project to make ‘progress’ using this forum to steer people on the network toward Azure. And using their influential employees to influence the discussions.
I get that this is how society works: people influence each other and it behooves an organization to survive—by persuading people through any means it can.
No, wait—sorry. Not through ‘any’ means. For example, using subterfuge will often backfire. It is a dangerous technique, innit? Say I hired a bunch of eager fellas to go on news sites and forums, to bring up ‘Kicks Condor’—to link to me, fawn about me, endlessly recontextualize me—this is what is happening to you, this is why you are here, you are entrapped in my game—the unique ‘Kicks Condor’ brand with its iconic sign on a pixel chair. Have you heard? He’s rumbling up—he’s ascendant. There is a certain measurable mindshare now emerging on the flatscreens. Why, it’s more dazzling and varied than I myself had previously dictated to my personal autonomous pocket assistant! (Can this be happening to me??) Look at the pixel chair. You’ll see it again soon.
Question: does gaming the algorithm undermine the algorithm? Or is it the point of the algorithm? I’m asking all of you out there—is the algorithm designed to continue feeding us the same narrative that we are already upvoting? Or can the upvotes trend away?
Or are the upvotes just bullets in some game of Fortnite where Satya Nadella is spraying us from high above with his army of toadies that have spammed the server so that he is not just one squad—but all the squads logged in—at least for the next two minutes? Until Eric Schmidt logs on and mows down all the independent links running for cover?
I’m not sure if I can say that they are manipulating the feed—but having spent some time on the ‘new’ page, it only takes about three votes to push something toward the front page. If you have ten people doing this, then you are gaming the algo. Hobbyists won’t have this kind of paid workforce. And it’s interesting how openly he discusses molding that community as if it’s his medium.
In case you haven’t heard of it Hacker News is a text-only link aggregator, a kind of proto-Reddit that has a ton of homebrew charm along with straight-up startup culture hustling. It has remained one of the more reliable sources of good shit. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I am very tied up trying to finish mine, but you’re doing a lot of good writing and I wish I was done so I we could be synced up on this.
I think the other question we need to ask is: how do we make a directory that’s not a directory? Like: is there a new kind of directory that is an evolution of the tried format? And I think the main point of pain is having to enter this giant catalog through a straw.
Just like Google is ‘entered into’ through a few search words—terms that rarely hit the mark and need to be gamed—could the directory widen the straw somehow? This is what is done by providing a hierarchy—but I also wonder if there are other novel forms. Like: say the directory changed day-by-day to suggest common categories or to show where I’ve been editing or to suggest a few categories.
I also wonder if a ‘pinned post’ might be useful: here are a few suggested categories, here’s one I added recently that’s kind of sweet, here are a few links that I’m considering throwing out.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
‘Constructing a body of hypertext over time—such as with blogs or wikis—with an emphasis on the strengths of linking (within and without the text) and rich formatting.’
‘Constructing a body of hypertext over time—such as with blogs or wikis—with an emphasis on the strengths of linking (within and without the text) and rich formatting.’
A superset of blogging and wiki creation, as well as movements like the Indieweb and, to some degree, federated networks.
Does it include social networks like Twitter and Mastodon? Sure, depends on what you’re doing. If that network is helping you build a body of hypertext, is keeping you sufficiently ‘linked’ and gives you enough of an ability to format the text, then ‘super’—you are hypertexting in your way.
Although:
Ton Zijlstra:
At some point social software morphed into social media, and its original potential and value as informal learning tools was lost in my eyes.
I hope it goes without saying that Twitter is a limited form of hypertexting. It underutilizes the tech—that’s its whole point, right?
You can compartmentalize your various writings, though.
Jennifer Hill:
And you’re probably all sitting there and you’re like, “This girl wants me to delete Facebook, Instagram, Twitter… I got a following! I got a brand!”No, that’s not what I’m saying. You have two selves. You have a career self, who—I’m pretty sure all of us have to use Facebook, Instagram and Twitter for work or Medium or whatever other platform in the world you want to use—and then you have your personal self that knows the things that they’re doing. And what I’m speaking to right know is your personal self. You know, I understand you gotta make money, gotta make that dime…
But the point of the term is not to disqualify a certain technology or to try to channel disgust or disdain into something new—that’s exactly why the term is envisioned as a superset. I am extracting this term from what I am seeing develop on the Web.
A superset is the inversion of a subset. So, rather than dividing a topic into further subtopics—we combine related topics into a new ‘super’ topic. By redrawing the lines of the topic, it is possible to discover new subsets within the superset or to work with folks across the topic as a whole.
In this case, the superset seems superuseful since the division lines between the hypertext niches are almost entirely structural. (This isn’t entirely true: some structures imply, for example, centralization. A feed of interleaved user ‘stuff’ is done most simply by a single network housing that data—at least at first.)
I’m not even sure the subsets actually exist. It is already all hypertext that conforms to a variety of possible structures:

The blog (feed) and the wiki (ad-hoc) might not actually be different—despite that we think of wikis as being multi-writer (the original wikis anyone could edit, without respect to any record of permanent trolling demerits) and using a simplified markup that made linking fluid while writing—a blog can do what a wiki can do and vice versa.
By decoupling the hypertext from the implied structure of a wiki or blog, I can now look at these structures as mere arrangements of my hypertextual body.
I think it’s worth repeating the criteria of ‘hypertexting’ so that it can be either corrected or remain crystal clear.
There is nothing new at all here—in fact, it’s all becoming very old—but the superset distinction allow us to draw attention to the ‘body’ rather than the blog ‘post’ or the wiki ‘page’ and to ask: ‘what are we creating here?’ The body itself is a superset—and ‘hypertexting’ calls into focus what the work as a whole can be from a higher vantage point.
These three attributes imply an effort that goes beyond writing alone. The first creates a body whose length is practically infinite—no reader will likely consume it all. The second indicates that much research (both external and self-research) is required. And the third gives a sense of bottomless innovation to the publishing interface—in fact, as long as the body is able to remain intact, it can be published by anyone exactly as it is intended, as long as the browser remains compatible, which it has done remarkably well so far.
In addition, this gives us the impetus to preserve the browser’s life and compatibility, such that these bodies are kept alive.
Creating a body this large demands the ability to shape the structure. This is the problem: how do I begin to approach your giant monolith of hypertext beyond just reading your two or three latest posts?
What I would like to highlight is the ability of the author to use the ‘body’, its linking and formatting, to shape the structure. To infoshape.[1]
Link directories are clearly a part of this superset. Delicious and Pinboard themselves act as hypertexting swarms that work to connect the bodies. Maybe these connections fill holes in the body—maybe they act as introductions between bodies. They are a way to shape the info and annotate it slightly.
h0p3: I’m actually annoyed when people call my wiki a blog, since it is obviously not that to me. Of course, the fool in me starts wondering what exactly on the web doesn’t count as hypertexting? What doesn’t have a single entry point?
The home page is definitely the curated entry point. But it’s not just that entry point that’s important—the points that go deeper from there are important. h0p3’s home page was initially the most important thing to me. But now it’s the ‘recent changes’ page and the bookmarks I have that indicate where I intend to next explore further. Sometimes he is a blog, sometimes he is a wiki. Sorry, man!
So, (tentatively,) let’s look at three aspects of your hypertext:
To bring this into practice, here are a few interesting ways I’ve seen this play out:
Zylstra.org: This blog builds on itself day to day. In a way, posts become redundant because Ton is very careful to rewrite the same idea in different ways—to be sure it’s understood. I have read articles from 2008 that are only subtly different from others in 2018. But this makes sense—his message hasn’t been received yet. On top of this, he has a small directory for reading through his writings. I found this perfectly useful. You can do this kind of thing by hand, if you need to.
h0p3: I guarantee you’ve never seen a wiki used this way—as a backup for physical letters, as a way of messaging people, of writing drafts in public, of keeping detailed link logs, chat logs—it’s all in there. Links are used liberally throughout everything, so that you can track h0p3’s growing nomenclature.
More than half of hypertexting is the reading behind it—because if you are hypertexting in isolation, then you are missing out on a world of links.
Ton:
I treat blogging as thinking out loud and extending/building on others blogposts as conversation. Conversations that are distributed over multiple websites and over time, distributed conversations.
What you might think of as ‘advanced hypertexting’ simply allows the shaping of the hypertext. Could we go beyond that?
To me, this is a great advantage of the superset. If the platform could see itself less as being a blog or a wiki or a directory, but as a collection of hypertexts that can be shaped, perhaps by hypertexts themselves. (Wikis—and TiddlyWiki in particular—have long had this abililty to make a page that displays the other pages as a blog. And some wikis allow you to include pages in other pages.)
The advanced hypertexting doesn’t end with the wiki—it’s just one way. I think Tumblr was initially on to something—aesthetic and piece layout are important here. Now add the ‘advanced’ hypertexting and what do you have?
(This is an unfinished steno—it could use a survey of the hypertexting field here. And it will be interesting to see where things go over the next six months. I will have to revisit this after I learn more.)
(I think the other missing discussion is how ‘ephemeral’ fragments fit into this. See also: Blogging.)
The other side of this coin is Infostrats—the reading of hypertext. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Cool, yes, the alert worked! That alone is very worthwhile and goes a long way toward discovery. In a way, I think this is the most idealized form—you’ve just done the equivalent of “Hey, check this out” and I am very fortunate that I get to read your reasoning rather than to simply see a like in my box.
I like that Sebastiaan’s end goal is to discover a person and not just CONTENT. To some extent the networks do this: mostly they promote trending squares of blurbs and images, but sometimes you see a note: “Follow these three people.” But you have no idea why and it’s not always based on similarity of our link neighborhoods, but based on geographical closeness or crossing some popularity threshold or your search terms and so on.
I don’t want to be so allergic to social networks that I can’t see the positive tools—bubbling up blurbs and images can be good fun, liking things is effortless nudging—but I think the Indieweb has already improved on this because its protocols are so light that it forces the human connections. (The ‘homebrew website’ clubs are the opposite of viral marketing.) You could see these as counterproductive—but the problem with ‘productive’ protocols is that they become so saturated as to be useless. Google, for instance, is so good that it is useless.
I still think algorithms are tremendously useful, particularly when the hypertexter controls the algo. And Sebastiaan is toying with this. I wonder to what degree his query language could simplified as to be more widely useful. Perhaps there is an Excel-type language that could become the dials for the ‘archivist’/‘librarian’/‘curator’ role.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Pinboard and Indieweb.xyz as clustering tools.
Ok ok, one other thing that has dawned on me: it’s not just the emergent connections between writers that is salient when clustering. It’s the connections between readers as well! (This is one thing that Google cannot possibly capture.)
To akaKenSmith’s point:
Having found each other, kindred parties need a work space where they can develop shared understandings.
The old Delicious was this kind of workspace for readers - a similar effort can be found in Pinboard.
One interesting thing I like to do with Pinboard is to look up a link - say ‘The Zymoglyphic Musem’ (results here) and then look at the other bookmarks for those who found the link. For example, the user PistachioRoux.
All of those links are now related to ‘The Zymoglyphic Museum’ by virtue of being in the realm of interest of PistachioRoux. YouTube uses these sorts of algorithms to find related videos by matching your realms of interest with someone else’s. However, in the process, that person is removed. (Or ‘those people’, more appropriately.) PistachioRoux is removed.
But perhaps PistachioRoux is the most interesting part of the discovery.
Particularly in a world which is becoming dominated by writers rather than readers - maybe the discovery of valuable readers is part of this.
Say a post tagged with #how_to #mk #fix_stabs could be crawled and collected into a single mechanical keyboard maintenance page. All that really calls for is emergent keywords from communities and tagging posts which bloggers can do and automations can assists with.
This does sound a lot like Indieweb.xyz, as @jgmac1106 mentioned. The concept is simple:
So the emergence should come from blogs clustering around a given URL.
I’ve been wondering if they could do a similar thing with http://www.adfreeblog.org/ - a ‘general’ blog community could be established around a simple ideal like that.
Might look like this:
The adfreeblog.org home page then becomes a directory of the community. So, kind of like a webring, but actually organized. With Twitter cards and such floating in the metadata, it is probably much easier to extrapolate a good directory entry.
Spam is an issue with this approach - but it’s a start toward discovery. There aren’t a whole lot of ways for a blog to jump out from the aether and say, “I’m over here - blogging about keyboards too!” And, in a way, the efforts to squash abuse and harassment are making it more difficult.
This can become an important component in the new discovery system like how awesome-blahblah github repos are playing a key role in open source discovery.
I think it’s important to point out, though, that ‘awesome’ directories are intended to be human-curated, not generative. They feel like a modern incarnation of the old ‘expert’ pages.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

glitchyowl, the future of 'people'.
jack & tals, hipster bait oracles.
maya.land, MAYA DOT LAND.
hypertext 2020 pals: h0p3 level 99 madman + ᛝ ᛝ ᛝ — lucid highly classified scribbles + consummate waifuist chameleon.
yesterweblings: sadness, snufkin, sprite, tonicfunk, siiiimon, shiloh.
surfpals: dang, robin sloan, marijn, nadia eghbal, elliott dot computer, laurel schwulst, subpixel.space (toby), things by j, gyford, also joe jenett (of linkport), brad enslen (of indieseek).
fond friends: jacky.wtf, fogknife, eli, tiv.today, j.greg, box vox, whimsy.space, caesar naples.
constantly: nathalie lawhead, 'web curios' AND waxy
indieweb: .xyz, c.rwr, boffosocko.
nostalgia: geocities.institute, bad cmd, ~jonbell.
true hackers: ccc.de, fffff.at, voja antonić, cnlohr, esoteric.codes.
chips: zeptobars, scargill, 41j.
neil c. "some..."
the world or cate le bon you pick.
all my other links are now at href.cool.





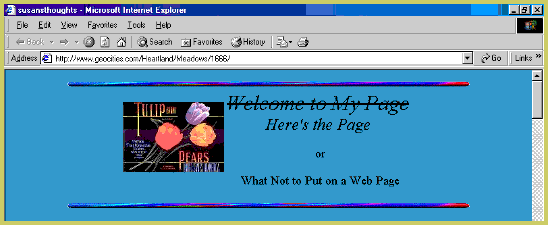


Reply:
His Wordpress blog gets Webmentions.
This is mostly a test comment. Mostly just saying hello!
But I also need to watch some of these films. I put off watching Beat Takeshi, instead going for the films of Katsuhito Ishii and stuff like Happiness of the Katakuris and Survive Style 5+. Need to at least watch this one, though.