12 Oct 2018
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.


This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.


It’s good to be a little ‘river’ of thoughts—apart from the estuaries.
Inspired by the concept of Ripped Sheets of Paper, I began to see a new blog design in my mind that departed from all the current trends. (Related: Things We Left in the Old Web.)
The large majority of blogs and social media feeds out there are:
So, yeah, no wonder the Web has deteriorated! We just don’t care. It’s understandable—we experimented for a good ten or twenty years. I guess that’s why I wanted this site to border on bizarre—to try to reach for the other extreme without simply aspiring to brutalism.
To show that leaving social media can free you to build your own special place on the web. I have no reason to scream and war here in order to stand apart.
When I started laying out the main ‘river’ of strips on my various feed pages—here’s my August archive, for instance—I started to want the different posts to have a greater impact on the page based on what they were.

A tweet-style note thing should be tiny. It’s a mere thought.
A reply to someone might be longer, depending on the quality of the ideas within it.
And the long essays take a great length of time to craft—they should have the marquee.
It began to remind me of the aging ‘tag cloud’. Except that I couldn’t stand tag clouds because the small text in the cloud was always too small! And they also became stale—they always use the same layout. (It would be interesting to rethink the tag cloud—maybe with this ‘river’ in mind!)
Even though these ‘river’-style feeds are slender and light on metadata—for instance, the ‘river’ is very light on date and tagging info—it’s all there. All the metadata and post content is in the HTML. This is so that I can pop up the full post immediately. But also: that stuff is the microformats!
Why bother with microformats? I remember this technology coming out like a decade ago and—it went nowhere!
But, no, they are actually coming into stride. They allow me to syndicate and reply on micro.blog without leaving my site. I can reply to all my webfriends in like fashion. They have added a lot to blogging in these times—look up ‘Indieweb’.
Honestly, they make this blog worth using. For me. I feel like the design should be for you; the semantic structure is for me.
This lead to a happy coalescing of the design and the structure: I could load individual posts on a windowing layer over the home page. This is a kickback to the old DHTML windowing sites of yesteryear. (And, in part, inspired by the zine at whimsy.space.)
What’s more—nothing (except the archives dropdown, I should say) is broken if Javascript is off. You can still center-click on the square blog post cards to launch them in a tab. URLs in the browser should line up properly without filling your history with crap.
I do have some new kinds of post layouts that will be cropping up here are there—such as how this article is made of individual tiles. But it all flattens to simple HTML where I need it to.
One of the struggles of the modern Indieweb is to have uniqueness and flair without sacrificing function. I have to do a lot of customization to integrate with Twitter, micro.blog and RSS. But I hope you will not need to work around me. So that remains to be seen.
At any rate: thankyou! So many of you that I correspond with offered juicy
conversations that stimulated this new design. My muse has always been Life
Itself. The experiences and conversations all around --> inspiration!
I feel fortunate to any eyes that wipe across my sentences from time to time.
Time to get back to linking to you.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
We talk about the privacy and data ownership of the Old Web, but I think there are other sweet angles we left off there. I still hate the word blog, though.
The Old Web isn’t dead. It just got old enough that it constantly seems to leave the spreadsheet with all of its passwords open on the desktop. It is sinking into the sofa while images of a low-bitrate Spaghetti Western dance in its bifocals.
We decry the loss of privacy and data ownership that seemed to be there in the Old Web. And we always wish there had been security. However, there are other things we left in the pockets of that Old Gray Web on the couch.
It seems that everything is white and blue in the present day. We’ve settled on these neutral colors, in case we need to sell it all. The old garish animated construction cones and embedded MIDI files are relegated to Neocities now—and who even cares what that is?

When we post, we post a few words. A picture and a few words. Some gray words on white. With a little blue.
This is one reason I was happy to see RSS fall out of favor. I don’t really want to read everything in Arial, gray on white with a little blue. Blog posts that were beautifully arranged in their homes, now stuffed together into a makeshift public shelter of dreary gray and white and chalked around with a little line of blue.
Did Google’s killing Reader kill the web? Or did Reader at least do some initial trial strangling?

We had been bitten too deeply by Myspace—its many glittery backgrounds and flame-filled Lightning McQueen backgrounds, golden cash symbol backgrounds and spinning Cool Ranch chip backgrounds. (Incidentally, some of this made a return with Subreddit style; 4chan and creepypastas never left the Old Web.)
I always wondered if the term “blog” was supposed make the term “home page” sound cooler. They both empitomize the idyllic Early Internet. Maybe the idea of “home” just IS corny—you only ever see it cross-stitched.
We moved on to a cosmopolitan empire, where we’re all living in the street. My house is full of your shit. And my uncles’ and aunts’ shit. And The Donald’s, of course, and the sad, desperate slideshows that Facebook makes for me in its spare time—it’s been basking in my shit again, trying to find some meaning in those three pictures I posted of a metal chair I spray-painted. It turns them over and fades them out again and again to try to stir some vital force. It all ends too quick—I’m trying here, but you’re not yet worth a slideshow, kid.
Gah, how I miss a good arm’s length. Between myself and all those people, bots and algorithms analyzing me for the little fractions of a second I might get. But what am I talking about? I have a blog and you’re standing on it right now! Or maybe you’re not. It gets lonely out here and I’m talking to myself again. The handful of devoted Baidubots, who quietly read the journals I leave on the stoop, look up but don’t even want to admit they’re there.
Reddit helped this situation so much. You could have a blog AND have a public place to leave a card!
The trouble is that Reddit has become the Big Blog. You are welcome to post your stuff there. But it’s usually in gray and white with a little blue—so that I lose a sense of who I’m reading exactly, who they are and where they call home. Reddit isn’t keen on a link to your blog without an acceptable amount of foreplay. You’re not yourself, you’re a Redditor—ten to twelve letters with a little bit of flair, maybe a cake, maybe a gold star. Could I be so lucky?

This might be reaching: I think an actual home—a blog or a home page—gave people time to represent themselves. In a stream of faces, you have to leap up from the river and shout HEY, throw a stick before the current pushes on. That picture has to have all of you in there.
Twitter has done well with this. You can find yourself reading someone’s history there. But Facebook, Instagram, Reddit—these all leave you crammed in the subway.

The Web—Old Web and The Now—it’s all a public place. Every page is an exhibition. Maybe Reddit has it right. By draining away the individual to a few letters, it becomes all about the message that they post. It hearkens back to mailing lists, when all you knew was a person’s From field. Though there were signatures, too, I suppose.
I think this has blossomed into a nice devotion to their community, because a Redditor’s works are tied up there. Do Redditors ever wish their stuff was home—where they could style it, save it, share it elsewhere?
I was recently impressed by something in the FAQ for a service called Bridgy:
How much does it cost?
Nothing! We have great day jobs, and Bridgy is small, so thanks to App Engine, it doesn’t cost much to run. We don’t need donations, promise.
This too felt very Old Web. Part of the tension in the modern Web is that we expect free in a billions-dollar industry.
When one company is taking on everyone’s blogs and pictures and witty repasts, that takes a toll. But the cottage tilde blogs of yesteryear came with your Internet connection.
It was an age of building things. Mostly little communities that had to be sought out. You had your phpBBs out there and blogs for different topics that acted like subreddits, but weren’t definitive. You built your own brick in this.
It sounds like I’m asking for the suburbs back. We built the ideal metropolis—now move back to the suburbs? What for? The Arcade Fire once sang a song about how much that sucks!

I think it’s more like a grassroots community thing vs. a corporate complex we can all live in. You can see the advantage in a community like BoardGameGeek, which hasn’t found its equivalent in Facebook and Reddit and so on. It houses a community tailored to its topic—every board game has its rules questions and its variants, so forums are tailored to this. You can search through the tree of associations—who designed what game and what other games and expansions did they produce?
Yes, it’s gray and white with a LOT of blue. It’s graceless in a way. But it’s managed to stay alive and independent. And it coexists with Reddit. They link back and forth and have a grand old time. (BGG also encourages posting on a forum rather than on your blog.)
It feels like there’s still building to do. No BGG isn’t ideal—but what does it become? Communities can still build out their facilities. I wonder what happened with the maker community. Hackaday seems to link mostly to YouTube and Instructables. Top notch work is still posted there and all around us (and at /r/diy.) It just seems that the will to “make” your web has left this crowd.
I guess this brings us to the Indieweb where you can probably still call each other Netizens and bemoan the death of RSS. Even though it’s been around since 2013, I see a spark of hope in this ragtag group of HTMLists. (Why isn’t “ragtag” some kind of microformat for the homeless?)
Now, certainly the Old Web had its spam and trolls and barriers. Discovering each other from across the Web has always been difficult. At least millions of people can get on Twitter and attempt to flag down Robert Downey Jr. in realtime. I just wonder if the little builders of the Web out there can start to reconnect.
I see a few projects out there that are in the vein of what I mean.
Webmentions.
At first I thought these
were very odd. Reading some one’s comment on your blog from their web page
seemed… a mess. But, after tinkering for a bit, I’m sold! Yes, blogs
are forced to conform if they want to participate—this is both a troublesome
barrier to entry and perhaps a too forceful structuring of a blog. It works for
me; for some others. If not for you, that’s fine.
The dat:// Project.
Dat transmits your blog
from your actual home. We all want decentralized, right? I don’t think we need
to be peer-to-peer to be decentralized. However, I’m impressed at the robustness
of this network—and the quality of the Beaker Browser.
I do think this protocol directly addresses the point about the $0.00 blog.
Jekyll, Metalsmith, etc.
Static sites still seem pretty crucial. The hosting fees are low. You can
handle high traffic in spurts. And you can publish anywhere without needing
to set up a bunch of software. So much innovation could still happen here!
Why am I not excited by Mastodon? Or Secure Scuttlebutt? Or micro.blog?
These seem like great projects. My main issue with them is that everything posted is, once again, reduced to gray and white with a bit o’ blue. (In Mastodon’s case, invert those colors.) They address decentralization, but not the other bits.
Now, just let me know you’re out there. If I link to you and you link to me, that’s a pretty good start I’d say.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

Sometimes your PWM pin is tied up doing SPI. You can still salvage the PWM timer itself, though.
Right now the spotlight is stolen by lovely chips like the ESP8266 and the BCM2835 (the chip powering the new Raspberry Pi Zero). However, personally, I still find myself spending a lot of time with the ATtiny44a. With 14 pins, it’s not as restrictive as the ATtiny85. Yet it’s still just a sliver of a chip. (And I confess to being a sucker for its numbering.)
My current project involves an RF circuit (the nRF24l01+) and an RGB LED. But the LED needed some of the same pins that the RF module needs. Can I use this chip?
The LED is controlled using PWM — pulse-width modulation — a technique for creating an analog signal from code. PWM creates a wave — a rise and a fall.
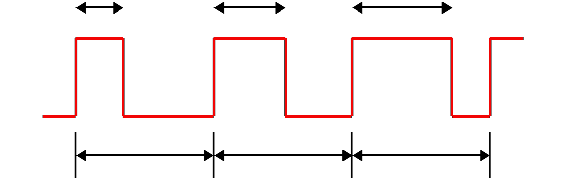
This involves a hardware timer — you toggle a few settings in the chip and it begins counting. When the timer crosses a certain threshold, it can cut the voltage. Change the threshold (the OCR) and you change the length of the wave. So, basically, if I set the OCR longer, I can get a higher voltage. If I set a lower OCR, I get a lower voltage.
I can have the PWM send voltage to the green pin on my RGB LED. And that pin can be either up at 3V (from the two AA batteries powering the ATtiny44a) or it can be down at zero — or PWM can do about anything in between.
My problem, though, was that the SPI pins — which I use to communicate with the RF chip — overlap my second set of PWM pins.
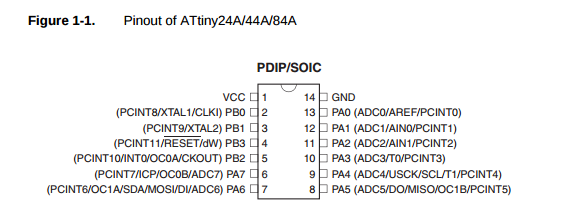
You see — pin 7 has multiple roles. It can be OC1A and it can also be DI. I’m already using its DI mode to communicate with the RF module. The OC1B pin is similarly tied up acting as DO.
I’m already using OC0A and OC0B for my green and blue pins. These pins correspond to TIMER0 — the 8-bit timer used to control those two PWM channels on OC0A and OC0B. To get this timer working, I followed a few steps:
// LED pins
#define RED_PIN PA0
#define GREEN_PIN PB2
#define BLUE_PIN PA7
Okay, here are the three pins I want to use. PB2 and PA7 are the TIMER0 pins I was just talking about. I’m going to use another one of the free pins (PA0) for the red pin if I can.
DDRA |= (1<<RED_PIN) | (1<<BLUE_PIN);
DDRB |= (1<<GREEN_PIN);
Obviously I need these pins to be outputs — they are going to be sending out this PWM wave. This code informs the Data Direction Register (DDR) that these pins are outputs. DDRA for PA0 and PA7. DDRB for PB2.
// Configure timer0 for fast PWM on PB2 and PA7.
TCCR0A = 3<<COM0A0 | 3<<COM0B0 // set on compare match, clear at BOTTOM
| 3<<WGM00; // mode 3: TOP is 0xFF, update at BOTTOM, overflow at MAX
TCCR0B = 0<<WGM02 | 3<<CS00; // Prescaler 0 /64
Alright. Yeah, so these are TIMER0’s PWM settings. We’re turning on mode 3 (fast PWM) and setting the frequency (the line about the prescaler.) I’m not going to go into any detail here. Suffice to say: it’s on.
// Set the green pin to 30% or so.
OCR0A = 0x1F;
// Set the blue pin to almost the max.
OCR0B = 0xFC;
And now I can just use OCR0A and OCR0B to the analog levels I need.
Most of these AVR chips have multiple timers and the ATtiny44a is no different — TIMER1 is a 16-bit timer with hardware PWM. Somehow I need to use this second timer to power th PWM on my red pin.
I could use software to kind of emulate what the hardware PWM does. Like using delays or something like that. The Make: AVR Programming book mentions using a timer’s interrupt to handcraft a hardware-based PWM.
This is problematic with a 16-bit timer, though. An 8-bit timer maxes out at 255. But a 16-bit timer maxes out at 65535. So it’ll take too long for the timer to overflow. I could lower the prescaler, but — I tried that, it’s still too slow.
Then I stumbled on mode 5. An 8-bit PWM for the 16-bit timer. What I can do is to run the 8-bit PWM on TIMER1 and not hook it up to the actual pin.
// Setup timer1 for handmade PWM on PA0.
TCCR1A = 1<<WGM10; // Fast PWM mode (8-bit)
// TOP is 0xFF, update at TOP, overflow at TOP
TCCR1B = 1<<WGM12 // + hi bits
| 3<<CS10; // Prescaler /64
Okay, now we have a second PWM that runs at the same speed as our first PWM.
What we’re going to do now is to hijaak the interrupts from TIMER1.
TIMSK1 |= 1<<OCIE1A | 1<<TOIE1;
Good, good. OCIE1A gives us an interrupt that will go off when we hit our threshold — same as OCR0A and OCR0B from earlier.
And TOIE1 supplies an interrupt for when the thing overflows — when it hits 255.
Now we manually change the voltage on the red pin.
ISR(TIM1_COMPA_vect) {
sbi(PORTA, RED_PIN);
}
ISR(TIM1_OVF_vect) {
cbi(PORTA, RED_PIN);
}
And we control red. It’s not going to be as fast as pure PWM, but it’s not a software PWM either.
I probably would have been better off to use the ATtiny2313 (which has PWM channels on separate pins from the SPI used by the RF) but I needed to lower cost as much as possible — 60¢ for the ATtiny44a was just right. This is a project funded by a small afterschool club stipend. I am trying to come up with some alternatives to the Makey Makey — which the kids enjoyed at first, but which alienated at least half of them by the end. So we’re going to play with radio frequencies instead.
I imagine there are better other solutions — probably even for this same chip — but I’m happy with the discovery that the PWM’s interrupts can be messed with. Moving away from Arduino’s analogWrite and toward manipulating registers directly is very freeing — in that I can exploit the chip’s full potential. It does come with the trade off that my code won’t run on another chip without a bunch of renaming — and perhaps rethinking everything.
Whatever the case, understanding the chip’s internals can only help out in the long run.
If you’d like to see the code in its full context, take a look through the Blippydot project.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Using Xcode 7’s new ‘sideloading’ to prototype.
OpenFL is good. It is pleasing. This we know. It makes computer programs. However, it is itself one of these programs. Gah! So it is actually very bad and frustrating! But oh how we love it still—we needn’t be primates.
Okay, let’s see how good it is with the new Xcode. This new Xcode 7 lets us sideload. Yes, it’s true. It lets us put our mobile programs into our mobile computers without anything special—without a premium account of any kind or any permission—as if we were now in control.
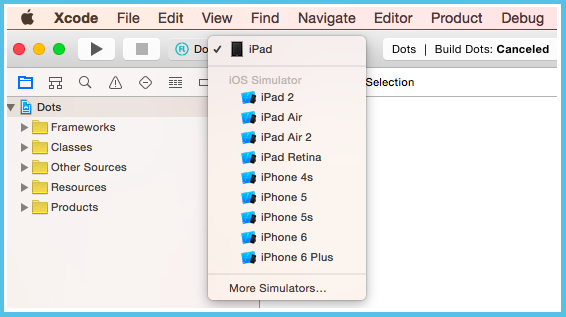
How it does this is by granting us little licenses through a plain, average Apple ID. We will need to tell Xcode about our account. And we will need to create these things called provisioning profiles for each one of our apps. And we will need to click the Fix Issue button many times. More to come on that.
For this, you must have OpenFL installed for Mac. Download the latest Haxe from that page and then run, in a Terminal:
$ haxelib install openfl
$ haxelib run openfl setup
Now, let’s get a sample going.
$ openfl create NyanCat iNyanCat
$ cd iNyanCat
OpenFL already has a number of sample programs—we’re copying the built-in NyanCat sample for our purposes. It’s true that Nyan Cat is not as funny as it used to be, but it is funny enough for Xcode to at least compile.
Edit the project.xml file in there.
<meta title="NyanCat" package="org.openfl.samples.nyancat"
version="1.0.0" company="OpenFL" />
Best to change the Bundle Identifier. (The package setting above.) This has to be globally unique (as in one-of-a-kind on all of planet Earth) so put something in that’s peculiar.
<meta title="NyanCat" package="com.kickscondor.nyancat"
version="1.0.0" company="OpenFL" />
I am also using the beta release of Xcode 7. So it was necessary to use xcode-select to point OpenFL in the right direction.
$ sudo xcode-select -s /Applications/Xcode-beta.app/Contents/Developer
Right ok. Back to trying to get this thing to come up.
$ openfl test ios
The openfl test ios command will be very chatty—screens and screens for several minutes. It is making something for us.
⛺ Plug in the iPad or iPhone at this point. If this is your first time connecting it, tell it to Trust this computer.
Hold up.
=== BUILD TARGET NyanCat OF PROJECT NyanCat WITH CONFIGURATION Re
lease ===
Check dependencies
Code Sign error: No matching provisioning profiles found: No prov
isioning profiles with a valid signing identity (i.e. certificate
and private key pair) matching the bundle identifier “com.kicksco
ndor.nyancat” were found.
CodeSign error: code signing is required for product type 'Applic
ation' in SDK 'iOS 9.0'
** BUILD FAILED **
The following build commands failed:
Check dependencies
(1 failure)
It’s true—this thing it’s saying about the provisioning profile is true. We have no provisioning profile. This isn’t confusing. All error messages are repellant, so, no, you can’t look directly at it, but it’s speaking the truth to you.
Normally, if your program is in Apple’s store, you would go to Apple’s site to fix this. You would follow something like these steps. But we want to use Xcode 7 for this.
If you haven’t intuited this already, you must install Xcode 7.
Go into the Export/iOS folder under the iNyanCat folder. Open the iNyanCat.xcodeproj file.
Clicking on the bolded NyanCat project name on the left side of Xcode will show a page with this at the top:
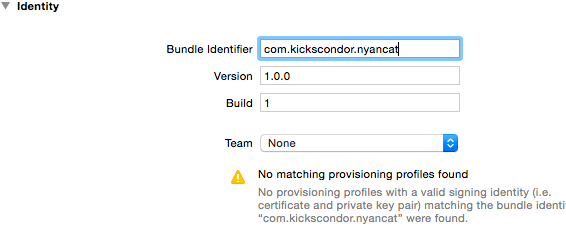
And now we create the team profile. From the Team selector, choose Add an account… and enter your Apple ID credentials.
A Fix Issue button will appear. Press it.

You may also want to be aware of the Deployment Target area.
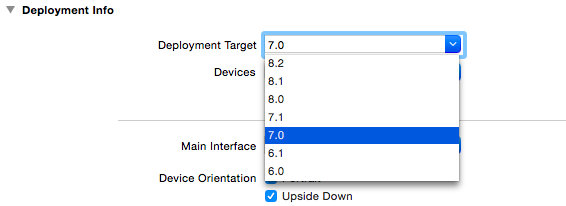
Sometimes upping the version on this will get you through problems.
At this point, you could just run the project from Xcode. (If you want to do that, just click on the arrow in the toolbar—the one that looks like a Play button—but be advised that it will take FOREVER to build.)
So, no, let’s not—let’s head back to the Terminal, as our build was almost complete when we had the provisioning profile problems.
$ openfl test ios
And it should appear on the iPad.
[ 60%] InspectingPackage
[ 60%] TakingInstallLock
[ 65%] PreflightingApplication
[ 65%] InstallingEmbeddedProfile
[ 70%] VerifyingApplication
[ 75%] CreatingContainer
[ 80%] InstallingApplication
[ 85%] PostflightingApplication
[ 90%] SandboxingApplication
[ 95%] GeneratingApplicationMap
[100%] Installed package /Users/kicks/Code/iNyanCat/Export/ios/bu
ild/Release-iphoneos/NyanCat.app
Yes, so basically now you can just stick to the Terminal and rebuild your app without needing to do anything with Xcode again.
The only issue that arises is if you want to create another new app.
You will need to edit the project.xml and change the Bundle Identifier in the new project. It’s a different app, it needs its own Id.
You will need to load the xcodeproj file into Xcode and hit Fix Issue again. This will assign this Bundle Identifier to your account. It’s like reserving a spot with Apple.
And then you should be in business for that project.
I had my share of problems—I will now relive these with you.
First, this one.
[....] Waiting up to 5 seconds for iOS device to be connected
[....] Using (null) (679c2f770cab0a8d8dc691595a8799b6aee88ca0).
------- Install phase -----
[ 0%] Found (null) connected through USB, beginning install
Assertion failed: (AMDeviceIsPaired(device)), function handle_
device, file ios-deploy.c, line 1500.
This means your iPad needs to trust. Unlock the iPad and you should see a popup: Trust this computer? Yes, please.
Next problem:
[ 60%] TakingInstallLock
[ 65%] PreflightingApplication
[ 65%] InstallingEmbeddedProfile
[ 70%] VerifyingApplication
AMDeviceInstallApplication failed: 0xE8008015: Your application
failed code-signing checks. Check your certificates, provisioning
profiles, and bundle ids.
I opened Xcode and discovered that the iPad Mini I had hooked up was listed as “ineligible.”
If your device is listed as “ineligible” then this means that the Xcode you’re using doesn’t include a Developer Disk Image for that specific version of iOS. In my case, I had 8.0.2 on the iPad Mini. What on earth causes a missing Developer Disk Image, though? Well, let’s see what’s included in my Xcode 7 installation:
$ ls /Applications/Xcode-beta.app/Contents/Developer/Platforms/iPhoneOS
.platform/DeviceSupport
6.0/ 7.0/ 8.1/ 8.3/ Latest@
6.1/ 7.1/ 8.2/ 9.0 (13A4280e)/
These are the versions I can sideload on to. As you can see, 8.0.2 is not present. The simplest way to solve this is for me to upgrade my iPad Mini to one of these versions.
You may also need to look for a newer Xcode release. I had problems with this because I had upgraded to iOS 8.4 on an iPad, but—as seen above—Xcode didn’t support iOS 8.4 yet. My device was ineligible because it was way too upgraded.
This problem also persisted when I hadn’t loaded symbol files onto the iPad Mini. Return to Xcode and load the xcodeproj file and ensure you can deploy to the device from there—once again, “Fix Issue” is your friend.
Here’s another one that plagued me for awhile.
[ 52%] CreatingStagingDirectory
[ 57%] ExtractingPackage
[ 60%] InspectingPackage
[ 60%] TakingInstallLock
[ 65%] PreflightingApplication
AMDeviceInstallApplication failed: -402653058
I tried upgrading the ios-deploy tool that comes with OpenFL. No good. I tried entering device information into the project.xml. Not that either.
I believe it went away when I started using Xcode to setup the provisioning profile. Xcode will connect to the device and put symbol files on it. You might try using Xcode’s arrow button (looks like a Play button on an audio player) and select your iPad in the area right next to the button. It will take a long time—but it only needs to happen once.
There also was this troublesome error that appeared while openfl test ios was running.
clang: error: -fembed-bitcode is not supported on versions of iOS
prior to 6.0
There are two possible solutions here. First, this is fixed in lime 2.4.8. So run haxelib list and ensure that lime is at least more recent than that. If not, run haxelib upgrade. 👈 Do this anyway—seems intellegent.
Second option is to simply open the XCode project and change the deployment target to (at least) iOS 6.0. (Bitcode enables the Apple Store to optimize your binary, at the cost of losing access to iOS 5.)
chmod: Unable to change file mode on /usr/lib/haxe/lib/lime/2,4,8
/templates/bin/ios-deploy: Operation not permitted
sh: /usr/lib/haxe/lib/lime/2,4,8/templates/bin/ios-deploy: Permis
sion denied
This one can be solved by manually making the file executable using sudo:
sudo chmod 0755 /usr/lib/haxe/lib/lime/2,4,8/templates/bin/ios-deploy
I also had difficulties getting the MongoDB driver for Haxe going under iOS. It worked fine for local testing (openfl test neko) but not for the device. I got compiler errors.
I forked the driver and made some alterations. Try this.
$ haxelib git mongodb-kicks https://github.com/kickscondor/mongo-haxe-driver
Add then add to your project.xml:
<haxelib name="mongodb-kicks" />
It is nice little touches like this, such as being able to bring in forked code from Github, that make OpenFL such a pleasure—even when it’s in a somewhat crabby mood about having to move itself onto such a suffocating platform such as Apple’s.
⛺ UPDATE: Recent versions of Xcode (7.2, for example) have a few different error messages that I thought I would cover also.
------- Install phase -----
[ 0%] Found XXX 'DeviceName' (...) connected through USB, beginning install
Assertion failed: (AMDeviceIsPaired(device)), function handle_device,
file ios-deploy.c, line 1500.
This one is a trust issue. Unlock your iPad or iPhone. You should see a dialog box asking if you want to trust this computer. Tap Trust.
You may also need to unplug the device and then plug it back in. This error can persist even after tapping Trust.
[ 65%] PreflightingApplication
[ 65%] InstallingEmbeddedProfile
[ 70%] VerifyingApplication
AMDeviceInstallApplication failed: 0xE8008016: Unknown error.
This is a code-signing issue. You want to use the Fix Issue button in Xcode. (See the And So Now It Just Works? section above for some instructions.)
Lastly, there’s a new popup on iOS that will block your app, with the title Untrusted Developer. The message continues: Your device management settings do not allow using apps from developer “iPhone Developer: [email protected] (XXXX)” on this iPad. You can allow using these apps in Settings.
The solution to this is in iOS Settings. Go to the Settings app. The General settings > tap Profile > tap [email protected] (or whatever the e-mail address was in the warning above.) Now trust [email protected]. And click Verify app. Go back to your app and it should run.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

While trying to get JoyLabz Makey Makey 1.2 to work with an iPad, I discovered there is no way to reprogram it.
It seems like this information hasn’t been disclosed quite enough as it should: Makey Makey’s version 1.2, produced by JoyLabz, cannot be reprogrammed with the Arduino software. In previous versions, you could customize the firmware — remap the keys, access the AVR chip directly — using an Arduino sketch.
🙌 NOTE: Dedokta on Reddit demonstrates how to make a Makey Makey.
Now, this isn’t necessarily bad: version 1.2 has a very nice way to remap the keys. This page here. You use alligator clips to connect the up and down arrows of the Makey Makey, as well as the left and right arrows, then plug it into the USB port. The remapping page then communicates with the Makey Makey through keyboard events. (See Communication.js.)
This is all very neat, but it might be nice to see warnings on firmware projects like this one that they only support pre-1.2 versions of the Makey Makey. (I realize the page refers to “Sparkfun’s version” but it might not be clear that there are two Makey Makeys floating about—it wasn’t to me.)
⛺ UPDATE: The text on the chip of the version 1.2 appears to read: PIC18F25K50. That would be this.
Now, how I came upon this problem was while experimenting with connecting the Makey Makey to an iPad. Instructions for doing this with the pre-1.2 Makey Makey are here in the forums—by one of the creators of the MM.
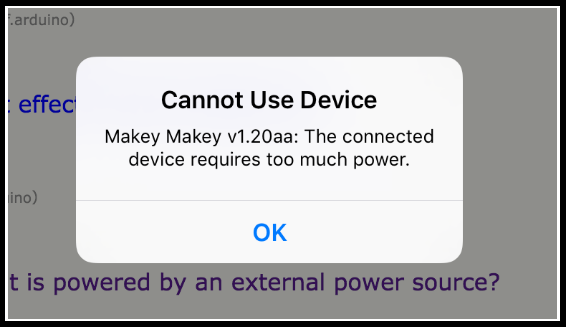
With the 1.2 version, it appears that the power draw is too great. I received this message with both an iPad Air and an original iPad Mini.
Obviously a Makey Makey isn’t quite as interesting with an iPad — but I was messing with potentially communicating through a custom app.
Anyway, without being able to recompile the firmware, the iPad seems no longer an option. (The forum post should note this as well, no?)
If you do end up trying to get a pre-1.2 Makey Makey working with the latest Arduino, I ran into many problems just getting the settings right. The github repos for the various Makey Makey firmwares are quite dated.
One of the first problems is getting boards.txt to find my avr compiler. I had this problem both on Linux and Windows. Here’s my boards.txt that finally clicked for me:
############################################################################
menu.cpu=Processor
############################################################################
################################ Makey Makey ###############################
############################################################################
makeymakey.name=SparkFun Makey Makey
makeymakey.build.board=AVR_MAKEYMAKEY
makeymakey.build.vid.0=0x1B4F
makeymakey.build.pid.0=0x2B74
makeymakey.build.vid.1=0x1B4F
makeymakey.build.pid.1=0x2B75
makeymakey.upload.tool=avrdude
makeymakey.upload.protocol=avr109
makeymakey.upload.maximum_size=28672
makeymakey.upload.speed=57600
makeymakey.upload.disable_flushing=true
makeymakey.upload.use_1200bps_touch=true
makeymakey.upload.wait_for_upload_port=true
makeymakey.bootloader.low_fuses=0xFF
makeymakey.bootloader.high_fuses=0xD8
makeymakey.bootloader.extended_fuses=0xF8
makeymakey.bootloader.file=caterina/Caterina-makeymakey.hex
makeymakey.bootloader.unlock_bits=0x3F
makeymakey.bootloader.lock_bits=0x2F
makeymakey.bootloader.tool=avrdude
makeymakey.build.mcu=atmega32u4
makeymakey.build.f_cpu=16000000L
makeymakey.build.vid=0x1B4F
makeymakey.build.pid=0x2B75
makeymakey.build.usb_product="SparkFun Makey Makey"
makeymakey.build.core=arduino
makeymakey.build.variant=MaKeyMaKey
makeymakey.build.extra_flags={build.usb_flags}
I also ended up copying the main Arduino platform.txt straight over.
Debugging this was difficult: arduino-builder was crashing (“panic: invalid memory address”) in create_build_options_map.go. This turned out to be a misspelled “arudino” in boards.txt. I later got null pointer exceptions coming from SerialUploader.java:78 — this was also due to using “arduino:avrdude” instead of just “avrdude” in platforms.txt.
I really need to start taking a look at using Ino to work with sketches instead of the Arduino software.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
So, perhaps tags (or subreddit-style categories) are good for initial categorization and then a more detailed hierarchy is good for a competent editor. I also wonder: how did you track expired links? Changed links? Would you indicate that a story got an update?
Reddit has done a similar thing with wikis. By giving each subreddit a wiki, many are able to arrange a heirarchical directory of links. I guess I’m wondering if a wiki is a suitable replacement for a directory. Or if the only difference is having a crawler attached. (Which is a formidable difference.)
An idea I’ve had with Indieweb.xyz is to have users submit a finer-grained category using the u-category class. So they could submit:
<a href="https://indieweb.xyz/en/startrek" class="u-syndication u-category">
xyz/startrek: Photos: DS9: Nog</a>
And it would place it in the permanent hierarchical directory (which crawls links to keep them fresh.) It feels like some moderation would be needed. But I am trying to stay away from that.
I appreciate your thoughtful replies. I am starting to both see how directories are present in our modern incarnation of the Web and desire some innovation for them.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A proof-of-concept for enjoying HTML includes.
It seems like the Beaker Browser has been making an attempt to provide tools so that you can create JavaScript apps that function literally without a server. Their Twitter-equivalent (‘fritter’) runs entirely in the browser—it simply aggregates a bunch of static dats that are out there. And when you post, Beaker is able to write to your personal dat. Which is then aggregated by all the others out there.
One of the key features of Beaker that allows this is the ‘fallback_page’ setting. This setting basically allows for simplified URL rewriting—by redirecting all 404s to an HTML page in your dat. In a way, this resembles mod_rewrite-type functionality in the browser!
What I’ve been wondering is: would it be possible to bring server-side includes to Beaker? So, yeah: browser-side includes. My patch to beaker-core is here. It’s very simple—but it works!
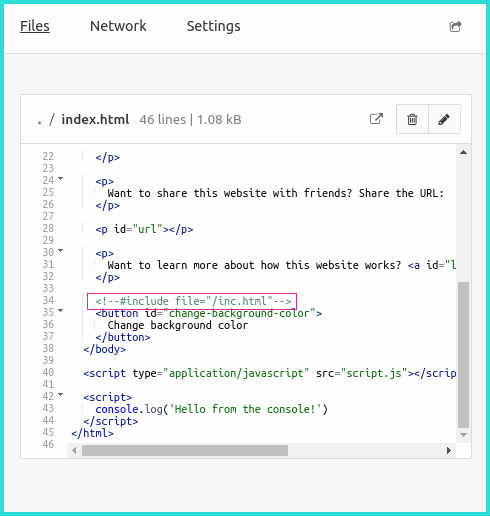
Here is Beaker editing the index.html of a new basic Website from its template. I’m including the line:
<!--#include file="inc.html"-->
This will instruct beaker to inline the inc.html contents from the same dat archive.
Its contents look like this:
<p style="color:red">TEST</p>
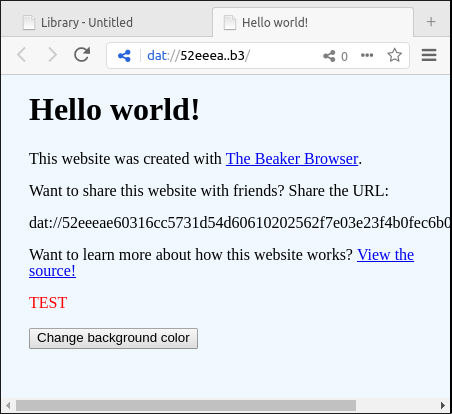
And here we see the HTML displayed in the browser.
I’m not sure. As I’ve been working with static HTML in dat, I’ve thought that it would be ‘nice’. But is ‘nice’ good enough?
Here are a few positives that I see:
Appeal to novices. Giving more power to HTML writers can lower the bar to building interesting things with Dat. Beaker has already shown that they are willing to flesh out JavaScript libraries to give hooks to all of us users out here. But there are many people who know HTML and not JavaScript. I think features for building the documents could be really useful.
Space savings. I think static blogs would appreciate the tools to break up HTML so that there could be fewer archive changes when layouts change subtly.
Showcase what Beaker is. Moving server-side includes into Beaker could demonstrate the lack of a need for an HTTP server in a concrete way. And perhaps there are other Apache/Nginx settings that could be safely brought to Beaker.
The negative is that Dat might need its own wget that understands a feature
like this. At any rate, I would be interested if others find any merit to
something like this. I realize the syntax is pretty old school—but it’s
already very standard and familiar, which seems beneficial.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Along with a discussion of personal encyclopedias.
There has been a small, barely discernable flurry of activity lately[1] around the idea of personal knowledge bases—in the same vicinity as personal wikis that I like to read. (I’ve been a fan of personal encyclopedias since discovering Samuel Johnson and, particularly, Thomas Browne, as a child—and am always on a search for the homes of these types of individuals in modernity.)
Nikita’s wiki is the most established of those I’ve seen so far, enhanced by the proximity of Nikita’s Learn Anything, which appears to be a kind of ‘awesome directory’[2] laid out in a hierarchical map.

Another project that came up was Ceasar Bautista’s Encyclopedia, which I installed to get a feel for. You add text files to this thing and it generates nice pages for them. However, it requires a bunch of supporting software, so most people are probably better served by TiddlyWiki. This encyclopedia’s main page is a simple search box—which would be a novel way of configuring a TiddlyWiki.
I view these kinds of personal directories as the connecting tissue of the Web. They are pure linkage, connecting the valuable parts. And they, in the sense that they curate and edit this material, are valuable and generous works. To be an industrious librarian, journalist or archivist is to enrich the species—to credit one’s sources and to simply pay attention to others.
I will also point you to the Meta Knowledge repo, which lists a number of similar sites out there. I am left wondering: where does this crowd congregate? Who can introduce me to them?
Mostly centering around these two discussion threads:
↩︎Discussed at The Awesome Directories. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This reminds me of these “useless web” sites—this being the primary one—that have managed to stay very popular. (A lot of YouTubers make videos of themselves clicking through this site and I often see kids at school using the site.) And it’s basically a webring. But it’s not a code-based one, it’s the opposite—it’s totally curated.
(Oh, also, the fellow who does this also works on a directory of “inspiring” projects that looks great. So, this is a person who is having some success playing with curated discovery projects.)
I think computers have completely blown it with discovery. The smartest minds have all been working on this for decades now and it has been a disaster. The question to me now is just: how do we equip our librarians? And I tend to think that we don’t need anything more—our technology is totally under-utilized.

However, there is one promising development that I see from the Microcast.club directory: the self-designed cards that show big images on each entry. The directory is using the itunes:image entry in the podcast RSS feed. This is fantastic because the curator can select/filter the directory entries—but the authors can customize their cards.
I wish RSS stylesheets would have caught on so I could offer this kind of thing for the Indieweb.xyz blog directory.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

The thing—the key—the realization that’s needed before you can write shaders. Really, I think this will help.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Continuing my discussion from Foundations of a Tiny Directory, I discuss the recent trend in ‘awesome’ directories.
All this recent discussion about link directories and one of the biggest innovations was sitting under my nose! The awesome-style directory, which I was reminded of by the Dat Project’s Awesome list.
An “awesome” list is—well, it isn’t described very well on the about page, which simply says: only awesome is awesome. I think the description here is a bit better:
Curated lists of awesome links around a specific topic.
The “awesome” part to me: these independently-managed directories are then brought together into a single, larger directory. Both at the master repo and at stylized versions of the master repo, such as AwesomeSearch.
In a way, there’s nothing more to say. You create a list of links. Make sure they are all awesome. Organize them under subtopics. And, for extra credit, write a sentence about each one.

Generally, awesome lists are hosted on Github. They are plain Markdown READMEs.
They use h2 and h3 headers for topics; ul tags for the link lists. They are
unstyled, reminiscent of a wiki.
This plain presentation is possibly to its benefit—you don’t stare at the directory, you move through it. It’s a conduit, designed to take you to the awesome things.
Awesome lists do not use tags; they are hierarchical. But they never nest too deeply. (Take the Testing Frameworks section under the JavaScript awesome list—it has a second level with topics like Frameworks annd Coverage.)
Sometimes the actual ul list of links will go down three or four levels.
But they’ve solved one of the major problems with hierarchical directories: needing to click too much to get down through the levels. The entire list is displayed on a single page. This is great.
The emphasis on “awesome” implies that this is not just a complete directory of the world’s links—just a list of those the editor finds value in. It also means that, in defense of each link, there’s usually a bit of explanatory text for that link. I think this is great too!!
The reason why most awesome lists use Github is because it allows people to submit links to the directory without having direct access to modify it. To submit, you make a copy of the directory, make your changes, then send back a pull request. The JavaScript awesome list has received 477 pull requests, with 224 approved for inclusion.
So this is starting to seem like a rebirth of the old “expert” pages (on sites like About.com). Except that there is no photo or bio of the expert.

As I’ve been browsing these lists, I’m starting to see that there is a wide variety of quality. In fact, one of the worst lists is the master list!! (It’s also the most difficult list to curate.)
I also think the lack of styling can be a detriment to these lists. Compare the Static Web Site awesome list with staticgen.com. The awesome list is definitely easier to scan. But the rich metadata gathered by the StaticGen site can be very helpful! Not the Twitter follower count—that is pointless. But it is interesting to see the popularity, because that can be very helpful sign of the community’s robustness around that software.
Anyway, I’m interested to see how these sites survive linkrot. I have a feeling we’re going to be left with a whole lot of broken awesome lists. But they’ve been very successful in bringing back small, niche directories. So perhaps we can expect some further innovations.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A prototype for the time being.
I’m sorry to be very ‘projecty’ today—I will get back to linking and surfing straightway. But, first, I need to share a prototype that I’ve been working on.
Our friend h0p3[1] has now filled his personal, public TiddlyWiki to the brim—a whopping 21 MEGAbyte file full of, oh, words. Phrases. Dark-triadic memetic, for instance. And I’m not eager for him to abandon this wiki to another system—and I’m not sure he can.
So, I’ve fashioned a doorway.
This is not a permanent mirror yet. Please don’t link to it.

Yes, there is also an archive page. I took these from his Github repo, which appears to go all the way back to the beginning.
Ok, yes, so it does have one other feature: it works with the browser cache. This means that if you load snapshot #623 and then load #624, it will not reload the entire wiki all over again—just the changes. This is because they are both based on the same snapshot (which is #618, to be precise.) So—if you are reading over the course of a month, you should only load the snapshot once.
Snapshots are taken once the changes go beyond 2 MB—though this can be tuned, of course.
Shrunk to 11% of its original size. This is done through the use of judicious diffs (or deltas). The code is in my TiddlyWiki-loader repository.
I picked up this project last week and kind of got sucked into it. I tried a number of approaches—both in snapshotting the thing and in loading the HTML.
I ended up with an IFRAME in the end. It was just so much faster to push a 21 MB string through IFRAME’s srcdoc property than to use stuff like innerHTML or parseHTML or all the other strategies.
Also: document.write (and document.open and document.close) seems immensely slow and unreliable. Perhaps I was doing it wrong? (You can look through the commit log on Github to find my old work.)
I originally thought I’d settled on splitting the wiki up into ~200 pieces that would be updated with changes each time the wiki gets synchronized. I got a fair bit into the algorithm here (and, again, this can be seen in the commit log—the kicksplit.py script.)
But two-hundred chunks of 21 MB is still 10k per chunk. And usually a single day of edits would result in twenty chunks being updated. This meant a single snapshot would be two megs. In a few days, we’re up to eight megs.
Once I went back to diffs and saw that a single day usually only comprised 20-50k of changes (and that this stayed consistent over the entire life of h0p3’s wiki,) I was convinced. The use of diffs also made it very simple to add an archives page.
In addition, this will help with TiddlyWikis that are shared on the Dat network[2]. Right now, if you have a Dat with a TiddlyWiki in it, it will grow in size just like the 6 gig folder I talked about in the last box. If you use this script, you can be down to a reasonable size. (I also believe I can get this to work directly from TiddlyWiki from inside of Beaker.)
And, so, yeah, here is a dat link you can enjoy: dat://38c211…a3/
I think that’s all that I’ll discuss here, for further technical details (and how to actually use it), see the README. I just want to offer help to my friends out there that are doing this kind of work and encourage anyone else who might be worried that hosting a public TiddlyWiki might drain too much bandwidth.
philosopher.life, dontchakno? I’m not going to type it in for ya. ↩︎
The network used by the Beaker Browser, which is one of my tultywits. ↩︎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A rundown of improvements—and the general mood—one month since opening Indieweb.xyz.
Ok, Indieweb.xyz has been open for a month! The point of the site is to give you a place to syndicate your essays and conversations where they’ll actually be seen.
In a way, it’s a silo—a central info container. Silos make it easy. You go there and dump stuff in. But, here in the Indieweb, we want No Central. We want Decentral. Which is more difficult because all these little sites and blogs out there have to work together—that’s tough!
Ok so, going to back to how this works: Brad Enslen and I have been posting our thoughts about how to innovate blog directories, search and webrings to the /en/linking sub on Indieweb.xyz. If you want to join the conversation, just send your posts there by including a link like this in your post:
<p><em>This was also posted to <a href="https://indieweb.xyz/en/linking"
class="u-syndication">/en/linking</a>.</em></p>
If your blog supports Webmentions, then Indieweb.xyz should be notified of the post when you publish it. But even if your blog doesn’t support Webmentions, you can just submit your link by hand.
One of my big projects lately has been to make it very easy for you all out there to participate. You no longer need a ton of what they call ‘microformats’ everywhere on your blog.
You literally just need to:
class="u-syndication" part, but I would still recommend it. If you
have multiple links to Indieweb.xyz in your post, the one marked u-syndication
will be preferred.)It helps if you have the microformats—this makes it easy to figure out who the
author of the post is and so on. But Indieweb.xyz will now fallback to
using HTML title tags (and RSS feed even) to figure out who is posting
and what they are posting.
A feature I’m incredibly excited about is the blog directory,
which lists all the blogs that post to Indieweb.xyz—and which also gives you a few hundred
characters to describe your blog! (It uses the description meta tag from
your blog’s home page.)
I think of Indieweb.xyz as an experiment in building a decentralized forum in which everyone contributes their bits. And Indieweb.xyz merges them together. It’s decentralized because you can easily switch all your Indieweb.xyz links to another site, send your Webmentions—and now THAT site will merge you into their community.
In a way, I’m starting to see it as a wiki where each person’s changes happen on their own blog. This blog directory is like a wiki page where everyone gets their little section to control. I’m going to expand this idea bit-by-bit over the next few months.
Just to clarify: the directory is updated whenever you send a Webmention, so if you change your blog description, resend one of your Webmentions to update it.
We are a long way off from solving abuse on our websites. We desperately want technology to solve this. But it is a human problem. I am starting to believe that the more we solve a problem with technology, the more human problems we create. (This has been generally true of pollution, human rights, ecology, quality of life, almost every human problem. There are, of course, fortuitous exceptions to this.)
Decentralization is somewhat fortuitous. Smaller, isolated communities are less of a target. The World Trade Tower is a large, appealing target. But Sandy Hook still happens. A smaller community can survive longer, but it will still degenerate—small communities often become hostile to outsiders (a.k.a newcomers).
So while a given Mastodon instance’s code of conduct provides a human solution—sudden, effortless removal of a terrorist—there will be false positives. I have been kicked out, hellbanned, ignored in communities many times—this isn’t an appeal for self-pity, just a note that moderation powers are often misdirected. I moved on to other communities—but I earnestly wanted to participate in some of those communities that I couldn’t seem to penetrate.
So, yeah: rules will be coming together. It’s all we have. I’m impressed that the Hacker News community has held together for so long, but maybe it’s too much of a monoculture. HN’s guidelines seem to work.
Last thing. A recent addition is a comment count on each submission. These comment counts are scraped from the blog post. It seems very “indieweb” to let the comments stay on the blog. The problem is that the microformats for comments are not widely supported and, well, they suck. It’s all just too complicated. You slightly change an HTML template and everything breaks.
Not to mention that I have no idea if the number is actually correct. Are these legit comments? Or is the number being spoofed?
I will also add that—if you submit a link to someone else’s blog, even if it’s an “indieweb” blog—the comment count will come from your blog. This is because the original entry might have been submitted by the author to a different sub. So your link contains the comments about that blog post for that sub.
Really tight microformat templates will need to become widespread for this to become really useful. In the meantime, it’s a curious little feature that I’m happy to spend a few characters on.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
A gateway to the Old Web and its sparkling, angelic imagery.
I try not to get too wrapped up in mere nostalgia here—I’m more interested in where the Web is going next than where it’s been. But, hell, then I fumble into a site like this one and I just get sucked up into the halcyon GIFs.
This site simply explores the full Geocities torrent, reviewing and screenshotting and digging up history. The archive gets tackled by the writers in thematic bites, such as sites that were last updated right after 9/11, tracking down construction cones, or denizens of the ‘Pentagon’ neighborhood.
Their restoration of the Papercat is really cool. Click on it. Yeah, check that out. Now here’s something. Get your pics scanned and I’ll mail you back? Oh, krikey, Dave (HBboy). What a time to be alive.
But, beyond that, there is a network of other blogs and sites connected to this one:

oocities.com/username.I was also happy to discover that the majority (all?) of the posts are done by Olia Lialina, who is one of the original net.artists—I admire her other work greatly! Ok, cool.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Previously known as ‘1080.plus’, this tri-dimensional VJ chat portal is still real—it is real.
What was a very underground tri-dimensional environment for exploring YouTube videos and playing Blackjack(?) together—hell, who knows what you’re SUPPOSED to do here—is now even more underground and abandoned now that it reappeared without any fanfare. I ADORED this place and went looking for it many months ago. Well—it’s back and now seems to have an otherworldly sister site i1os.
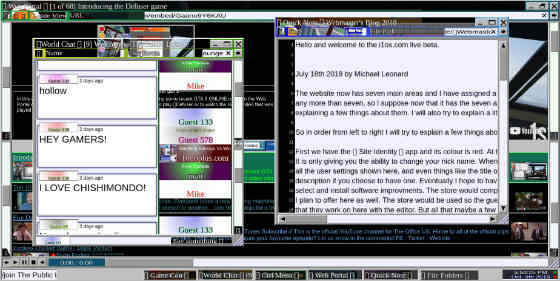
Strangely enough, the site was profiled in New York Magazine where the Canadian author (Michael Leonard) says 1080plus is “a project to make a multiplayer theater experience where you could join friends in a virtual world / virtual theater staring at the same virtual silver screen together, and talking about it as it plays.”
Ok, finally, something has survived of the old world.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
“Do not let my honesty become your enemy.” vs. “What if the secret discovered was a good one?”
Let’s also bring this in:
At last I understood that the way over, or through this dilemma, the unease at writing about ‘petty personal problems’ was to recognize that nothing is personal, in the sense that it is uniquely one’s own. Writing about oneself, one is writing about others, since your problems, pains, pleasures, emotions—and your extraordinary and remarkable ideas—can’t be yours alone.
— Doris Lessing, from her Introduction to The Golden Notebook, 1971
(Okay, time to get everyone else up to speed: I sent h0p3 a private e-mail—to determine
if there was any way of privately communicating with him. I did this partly to satisfy
my curiousity: he seems to post every chat log, e-mail and letter he sends—except
to immediate family members that have grandfathered-in immunity—or perhaps he just defaults to public mode unless a kind of formal agreement is established.)
(I also did this to simply converse privately. Since h0p3 has settled on a dogged insistence on Wikileaking his life, I am unsure how to have a personal relationship in public hypertext with this avatar. He says the avatar is competely, realistically human—it aspires to be—and I am finding out if it is. Am I starting from a place of distrust? Well, surely. But that’s minor. I am suspicious of BOTH of us. We want to believe these pixels are us—don’t we already know they aren’t?)
(Because, most importantly, there is you. Isn’t it awful to address you during a letter to my friend? I steal time spent on answers he wants. I talk about him as a third, which sounds condescending, simply because he is not us. And you could be anyone: an other, likely a reader, an agent.)
(Maybe it’s not about us at all. Maybe it’s about you. Ours is just a performance. And so there is no us, but just you.)
Let me start by responding to your brother:
He read the kickscondor letters in full (I didn’t realize he’d read it all, which is cool). He pointed to a shift in the tone of the writing. He said we were jerking each other off at first and then got to the meat’n’potatoes. He thinks I’ve been tested in the last section of the last letter. I think he’s right.
Heheh—it’s very true! I think there is a kind of jerking-ones-anothers-off process that has to happen before you’ll honestly read each other’s words, though. But there’s no doubt: I’m the one being tested here.
You have filled a wiki so deep that I can’t see the bottom—and it lands like a monolith; it looks like your beliefs, it is a flashing rainbow conduit. But I am still ripped pieces of paper that blow around in the wind and are lost in wild valleys. I think these things will stay this way.
Yes and HELLO to your brother! How can I send him a private e-mail? It’s very important that it be private. It is like when two of my friends meet and later I find them muttering unintelligibly by the bookcase. God—what are they saying?? What if even the Real U.S. Government and Amazon Alexa can’t seem to make it out??
I am going to publicly think about you, who you are, how you think, what you say, and what you do. Do you wish to be so open and honest? Do you really want to interact and be in contact with me? In this context, informed consent is your responsibility. Do not let my honesty become your enemy. You do not have to wrestle with me, but I hope you see I’m actually trying to radically cooperate with Humanity. How will you treat this naked madman in the desert?
(This bit is not from the letter I am replying to, but from Contact h0p3. I’m not sure I read the whole thing previously, but his rules of engagement are clearly spelled out. Please read this if you intend to strike up a conversation. I wonder if we could all use a page like this—somehow I can’t see myself doing this, as it feels in close proximity to a sign my neighbor has on her door: “DO NOT BRING DRUGS, ALCOHOL OR ANY ILLEGAL MATERIALS OR SUBSTANCES INTO THIS HOME!!” Such a note has the fragrance of a previous encounter all over it; there is a distinct banishment of the “you do you” from 2018—which may not actually exist.)
He concludes the letter:
In part, I aim to be so public simply because I don’t trust people in private. I think very poorly of most human specimens (including many versions of myself), but I desperately hope we find a way to become good human beings. I hope to protect and enable the percentage of legitimate altruists who exist in humanity; they deserve every ounce of my effort. They are truly constituted by Reason.
I play with my cards face-up on the table. In a way, I hope it has a kind of ripple effect in spreading awareness of what it means to be ourselves […]
Ok, so this I get. It seems feasible that a public performance of the private could shake out some disasters. It’s possible that we need everyone to weigh in on this. And we already have the benefit of your pupil Sphygmus (a reader like you out there—us—who stepped out of the ‘real’ to join us here).
On the other hand, this now adds infinite perspectives to demonize these conversations, to shame them, to hate them. I’ve honestly never had a chance in my life for someone to hate one of my private conversations—except for the other person (and even that has happened far too frequently.)
I think if I were to develop a seed of my own personal code (to stand in contrast to yours,) it is that I believe in well-mannered pseudonymity. Bonhomminity.
Secrets get such a bad name. We always discover horrible secrets. Thousands of them, stretching all the way up to the Pope himself? Or a document circulating the CIA describing a series of golden showers…
What if the secret discovered was a good one? And what if it stayed secret? Like a good joke kept to one’s self. Or between my love and I. Never to be sold off in a book or blog—kept inside.
I don’t imagine much is lost on a public inside joke? This is probably what Dan Harmon has with all of his fans. They all get to be in on it. It is the token of the group now. It is a special key. Millions may have the special key.
(Following is not a h0p3 quote.)
Do not sound a trumpet before thee, as the hypocrites do in the synagogues and in the streets, that they may have glory of men. Verily I say unto you, They have their reward.
Not considered: your private joke is heard by angels in Heaven!! (Sigh, further surveillance systems…)
Actually I quote this because there is something to it—the reward of public recognition does seem to pollute the pure giving of a private communication.
And what’s more: you have no idea whether I talk of you. Whether you get zero conversation hits or thousands. What I have read of yours. How I react to it—what I really think of you. (Do I know what I really think of you? Do I know when I’ve conversed about you?) How would it be helpful for either of us to know these things? And, worse, to know them forever.
Picture two computers scanning each other ports. These two daemons find each other and swap drive contents, RAM, video card states. Then they blink: blue, blinking red or bright white. They understand each other!
But what does it matter? Perhaps they can part ways now—there is no more data to exchange.
I must ask: do you simply FO desire to encourage me, or do you SO desire to FO desire to encourage me? The difference matters. There is a tension in this letter I’ve not been able to peel apart.
Boy, I don’t know yet. I like to think it’s way down—like zed order enouragement.
I think this only happens out of motivations like idle curiosity, amusement and meandering conversation. Which is to say: the greatest, most noble pursuits I can imagine. Convincing you IS NOTHING compared to these treasures!!
I hope to find: not truth, not love, not happiness, not even meaning—but ‘fire’.
And I guess I do hope to have gratitude, which is greater than happiness. And I think a desire to have immense gratitude for the idle curiosity, amusement and meandering conversation—that would be FO for me. I don’t know where that puts us. I am very serious about this. (And I am not just saying ‘I am very serious about this’ as a joke—it’s all very serious!)
Building trust and real relationships is exactly why I reveal myself to you and everyone else. I want people to see how I conduct myself and my relationships across the board.
My dad talks this way—to him, a conversation is a sacrament. Sometimes I am with him on that.
But other times I want to be in the dark of night with friends, carefully putting a pie in the road, as an example, since it is very spiritual to do so. Or eating different leaves and needles and recording reviews of the taste.
To simply swing alongside someone on a swingset is miraculous. To use one of those air seesaw things—where you sit across from each other and swing back and forth—I did that with my nephew a few weeks ago and he was wearing a hat that had a LEGO texture on it. He could have attached to a hell of different bricks! The feeling of amusement and ‘fire’ was there.
Of course, my worry about “how it feels” is that emotions can betray us. It’s very easy to confabulate. It’s a realm where I aim for reason to reign as much as possible.
Ok so three primary facets where we graph as opposites:
The unreasonable. The supernatural. The stuff of imagery. Perhaps symbolism is
there, between us. Just as you fear an emotion betraying you and guiding you into
delusion, I fear needing to act on perfectly rational orders that betray my
heart—that go against my experience of the world. (Sloppy sloppy work, Kicks!
Why am I rushing to codify someone? I think what’s happening is that I’m seeing
this dogmatism for transparency on his part and so I’m rushing to ascribe these other dogmatic
views—rasfarasfaaaaplagdaaaaahnono, no, so I don’t really care about this part
of the letter—in a way this serves to show that I was wrapped up much more deeply
in the visual part of this thing and rushing the text. As he has already said in
reply: “I worry you’ve not carefully represented my claims.” Yes! Can I rewind
slightly? I don’t think the head-to-headedness of this part of the correspondence
needs to be here—I have undermined connecting in favor of spiraling. Emotion (or
gamesmanship or something) has scattered the ripped pieces of paper. Oh to be
pure and kind as Sphygmus, help me, Sphygmus!)
Because of the events of my life, I am close to people who have been in unimaginably horrifying situations. It’s not that they’ve lost a child. It’s not that they’ve lost a spouse or that they’ve tried to kill themselves—it’s that they’ve lost their whole family. Everyone they held closest died. (Usually it’s a parent who lost their spouse and children—there are more people in this situation than you would think.)
Let rationality guide you through that catastrophe! (This is assinine.
I think I got worked up for some reason, not because of a disagreement with you
but because I got passionate and spiraled. I mean this is proof of the danger of
emotion—tempering it is a challenge for everyone.)
I will need to stop there. It starts to feel exploitative to talk in this way—to use their tragedy to make my point. But there are also stories that I want to talk about down the road, because they have happened in such quiet, without the notice of society—and maybe I see a reason to write them, because they have ‘fire’.
Swinging on a swingset is god damn vital! (Shut up. I don’t like that
this comes across as a heavy-handed point to be made. Be light-handed. Always let the
hand rise into the atmosphere.)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Thread about building link directories—sounds dry, but I am all about this right now.
Cool, cool.  Hearing this has made me ramp up my work on mine as well. Looking
forward to linking to each other when we get there.
Hearing this has made me ramp up my work on mine as well. Looking
forward to linking to each other when we get there.
I am nearing 200 links in my directory—that I’ve snapshotted and summarized—and my attitude toward the directory has changed a bit. At first, I simply thought, “Oh, I’ll just put any link in there that I like.” Which basically turns it into a big list of my bookmarks. (Which is fine—if it’s useful to me and helps the sites I really enjoy, then that’s a good angle to start with.)
However, I’m starting to see that I’m actually attempting to paint a picture of the Web—making a map of it, right? And so I’ve started branching out and including stuff that I may not visit all the time and that I may not even like, because I’m trying to show how ‘wide’ the Web is. As a result, I’ve started including a lot of controversial links across the spectrum of humanity—in order to make the directory more about the Web than it is about Me. (I’m a very passive person, so I tend to rule out posting anything inflammatory or controversial, because I have no idea what the ‘right’ side of an issue is and I just would usually rather not deal with it.)
Ok, so, it’s interesting how your previous sci-fi and horror directories weren’t at all about your preferences, but about mapping out a community. This is a lot tougher with a general-purpose directory because the Web is so big.
So, yeah, I wonder what your criteria are for what you are including. And what your mindset is while you are collecting and editing. I think it would be useful for us to write our thoughts so we can give some advice and encouragements to others who want to build their own web directories.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
The name is odd; the campiness is tuned in.
So this thing starts off as a kind of old-school banner ad but—scroll, scroll—it’s a link directory! Pretty sweet—I like that it’s just a bunch of tiles and you have to wonder what’s behind them. (And wondering about its creator.)
Like here’s a personal homepage that was crammed in there. The counter says only 40 people have been there. And you might say, “What is even there? Why would I even spend time here?” Is bouncy text not enough for you? Is being the 41ST PERSON not enough??
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Ok, got it. It’s interesting—we kind of have to do this on our personal sites
anyway. Like if I get a reply from myself further down the conversation, it’s
useful to just use the post I ‘own’ directly rather than go parsing myself. 
It’s kind of tough to get it all working by hand—but it’s also amazing, so I’ll take it!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Interesting—the ‘make use of’ part really doesn’t apply to what I’m doing because I’m not evaluating links on ‘usefulness’—I want links that are more of an experience or perspective. But I like that you’re doing that in yours. I think it will allow us to compare what draws people in—if that’s even possible.
Themes: Rebuilding the independent web, the web as our social network, alternatives to silos, security and privacy.
With mine, I’m specifically avoiding software and business links—because these dominate Google and already have a lot of directories. I’m not linking to technical posts of any kind, though I do have a section on free sites to use to participate on the Web and Indieweb.
My themes are more: unique sites, colorful sites, bizarre sites (to some extent) and thoughtful sites. I love those pages that I read and they were so profound or beautiful that my life changed just being there.
These first 100 links have been kinda from memory: so software to help a beginner build a website, computer security, better browsers, privacy search.
That’s sweet. I’ve been loving the links you’ve been finding (like millionshort and findx—to which I would add wiby perhaps) and so I will definitely use the directory. Vivaldi has been great—I’m following along, Brad.
On top of this, I have categories that I don’t want to leave blank, stuff I don’t have in my head anymore so I have to dig. Oh the rabbit holes! There are lots of things I need to dig up more on but it can wait till later.
Yeah, so, this is a good topic. I started a few categories that I’ve decided to hold off on. I have an ‘Animal’ category, for instance, but I don’t think I’ve got enough quality material to make it happen yet. I’m close, but I might hold off.
Like you, I found it useful to build my categories first, though. I’m only going two tiers deep. So I have a main category and then the actual category. I don’t put any links right under the top-level yet.
Incidentally, here are the classification systems that I springboard from:
I don’t want to overdo the hierarchy, because frankly I expect most people to use the search function anyway.
Huh—I am skipping the search. I guess I’ll have to rethink this. I also have so few links that a lot of searches will draw blanks.
I’m listing both websites and individual web pages (sometimes known as deep links) in the directory. Sometimes both. In essence I’m giving myself the flexibility to say, “I don’t know about the rest of the site, but this one post on blue widgets is brilliant.”
Same. In fact, sometimes I link to just an image or a video and those are marked as such.
A link may appear in more than one category if it is relevant.
I don’t do this—I tend to link to the second category in the entry’s description instead. I do have some meta categories like ‘Blogs’ and ‘Wikis’ that will list all websites of those types from all categories.
I do have some ‘secret’ categories that aren’t reachable from the hierarchy. For instance, I have a ‘Charlie McAlister’ secret section that goes into depth on his life—and which is only reachable from his link in the ‘Visuals/Zines’ category.
At some point I will go back and cross index categories that are relevant to each other.
Cool—not sure I have enough categories to do that. (Probably 30-40 categories.)
Link descriptions: Right now I’m just making sure the description has the keywords in it that are needed for people to find it. I’m not trying to write a review although sometimes I do editorialize.
This is where I go to town. I sometimes include five more links in the description. I am spending a lot of time making these juicy, giving history, including images. I may need to expand some of these into full-page articles.
The directory will be open for submissions at launch. Frankly, I’m not optimistic I will get a lot.
I think we need to look at this as long game. It might be good to give yourself a timeline to work with. Like I am giving Indieweb.xyz a year to see how it goes. I might go for two years. It requires a lot more maintenance and work because people interact with it—it’s not just static HTML.
With this directory, I am committing to 20 years. I am definitely going to keep it up for the long run. It is designed to be a portal to the somewhat permanent Web and it needs to be there longterm in order to work. This means I can play a long game and just build it gradually. Maintaining links is the hard part—but if I keep it small, it’s fine.
I’d really prefer that bloggers add their own blogs and write their own descriptions. For example how do I describe Kicks Condor’s blog or Chris Aldrich’s blog? Blogs like mine and yours and Chris’ are about a little bit of everything.
Well, here’s my entry for your blog so far:
Brad Enslen
https://ramblinggit.com/
Web/Meta Blog 10m
I bounce ideas back-and-forth with this fellow. He blogs about web
directories and web search---but in an effort to understand how else
we could be doing this. Our conversations led me to make this directory.
You might take umbrage with my description—it’s pretty low-key. I try not to pitch a site with too much fervor—if I say that every blog is ‘the best blog ever’ then it’s meaningless. But I also don’t want to judiciously decide that one is the best. I’d rather just say matter-of-factly why I visit a site. (I could see myself saying, “This is THE guy I go to when I want to read about organizing links and enhancing the Web these days.”)
But I think if the description is written by me, it’s more likely to be interesting because self-promotion will always come off as marketing—this entry just comes across as an informal recommendation, like you’d hear in a conversation.
You could also start with the description meta tag on your links.
It’s easy to Duckduck for cooking blogs and find them, but what about blogs that are about every topic under the sun? They are hard to find by keywords but they do need to be found.
Well, this is the advantage we have over Google. We can link to anything and it will be found because it’s never too lost in the directory—since we’re both only in the small hundreds of links.
Finally, there are topics I’m just not interested in or want to avoid: Politics, sex, religion – better served by a search engine. Sports? I can’t be bothered. But this too is cool, because there is room for sports, political and other niche directories. Just as there is room for thousands of small general directories.
Let’s hope!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Sweet! So this works identically to Salmentions?
Ok, let me see if I’ve got this right—if I reply to a reply that’s later in the chain, I try to track down the original post like this:
Load the URL I’m replying to.
If it has an u-in-reply-to link, load that page (repeat step 1 & 2, ad
finitum).
Once I hit the end of the chain, I am left with an array of the reply history.
This should work on micro.blog because the only actual h-entry on a reply’s
permalink is the ACTUAL reply—the other entries shown on the page are just
posts that won’t be picked up by the microformats parser? Pretty interesting
approach.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Ran across this note from 2013 that hates on ‘content’. From net.artist Olia Lialina. Relevant.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
But doesn’t receive them? Still—neat!
Sending Webmentions to other sites seems like an insane thing to turn down. Your blog software sends a simple message and now that blog can know to link back to you. (And go ahead and send pingbacks, too—way too easy.) But a site like this one, Lobste.rs, where there is a lot of discussion about a given link—seems even better, more advantageous, generally, usually, to bring the author in.
Now imagine if this continued:
And you could verify these Webmentions (and attach them to a user) by verifying that the Webmention source is listed in the user’s ‘about’ section.
Just a quick mention that this is how Indieweb.xyz works and I am very anxious to see if it’s possible to really have a community work this way! (I’m not sure I know of any other community that is entirely built ENTIRELY from blog and wiki crosstalk—maybe the deceased ‘bloglines’ was one?—‘is’/‘was’ there one?)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
‘One day my window was darkened by the form of a young hunter. The man was wearing leather and carrying a rifle. After looking at me for a moment, he came to my door and opened it without knocking. He stood in the shadow of the door and stared at me. His eyes were milky blue and his reddish beard hardly concealed his skin. I immediately took him for a half-wit and was terrified. He did nothing: after gazing at what was in the room, he shut the door behind him and went way.’
— from “The House Plans” by Lydia Davis, p53 in The Collected Stories
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Another one of those vids from the console hackers that inspires true joy — an SNES hacked to bring us Super Mario Maker. Watch what happens when the reins are handed over to Twitch chat.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
My personal strategy for handling HTML on the distributed Web.
So, HTML is a bit different on the distributed Web (the Dat network which the Beaker Browser uses, IPFS and so on) because your file history sticks around there. Normally on the Web, you upload your new website and it replaces the old one. With all of these other ‘webs’, it’s not that way—you add your new changes on top of the old site.
Things tend to pile up. You’re filing these networks with files. So, with a blog, for instance, there are these concerns:
Ultimately, I might end up delivering a pure JavaScript site on the Dat network. It seems very efficient to do that actually—this site weighs in at 19 MB normally, but a pure JavaScript version should be around 7 MB (with 5 MB of that being images.)
My interim solution is to mimick HTML includes. My tags look like this:
<link rel="include" href="/includes/header.html">
The code to load these is this:
document.addEventListener('DOMContentLoaded', function() {
let eles = document.querySelectorAll("link[rel='include']");
for (let i = 0; i < eles.length; i++) {
let ele = eles[i];
let xhr = new XMLHttpRequest()
xhr.onload = function() {
let frag = document.createRange().
createContextualFragment(this.responseText)
let seq = function () {
while (frag.children.length > 0) {
let c = frag.children[0]
if (c.tagName == "SCRIPT" && c.src) {
c.onload = seq
c.onerror = seq
}
ele.parentNode.insertBefore(c, ele);
if (c.onload == seq) {
break
}
}
}
seq()
}
xhr.open('GET', ele.href);
xhr.send();
}
})
You can put this anywhere on the page you want—in the <head> tags, in a
script that gets loaded. It will also load any scripts inside the HTML fragment
that gets loaded.
This change saved me 4 MB immediately. But, in the long run, the savings are much greater because my whole site doesn’t rebuild when I add a single tag (which shows up in the ‘archives’ box on the left-hand side of this site.)
I would have used ‘HTML imports’—but they aren’t supported by Firefox and are a bit weird for this (because they don’t actally put the HTML inside into the page.)
I am happy to anyone for improvements that can be made to this.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Took a look at your blog—it’s sweet! I will be sure to include it in my next href hunt. I enjoyed the article about Dat and am interested in finding others who write about practical uses of the ‘dweb’—unfortunately, many of the links on Tara Vancil’s directory are ‘broken’ (perhaps ‘vanished’ is more correct?) and I’m not sure how to discover more.
At any rate, good to meet you!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
The issues with Dat as an e-mail analogue.
Perhaps Dat simply isn’t designed for privacy—but it’s so close that I think it’s very useful to talk about the gaps. This is a very solid list of how Dat measures up for private groups—compared to an e-mail newsletter.
It seems to me that the main sticking point is that Dat is always accessible to the main network, whereas e-mail is inaccessible to the main network (except through windy routes.)
It occurs to me that maybe this is what Hyperswarm (a project by some of the Dat team) is attempting to add. If you can run a private Dat network, then you could have a shared folder detached from the main network that would be inaccessible. You’d probably need a password on top of that—but that seems analogous to, say, IMAP. You’d still need tools to access it, so it’s all entirely hypothetical, but yeah—cool thoughts, thank you!
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This is a great article! It follows all of the same things I put in my reply—which makes me nod my head, for sure—but it also goes into much more detail and thought, which I very much appreciate.
The war against the word ‘content’ is also rad. Yeah, keep that up.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
I’m starting to arrange my tags into a Sierpinski triangle—there are now three primary ones: hypertext, garage and elementary. These act as sub-blogs—other tags may be looked at as sub-sub-blogs to these, cross-sections to these three and assistive search until I find a ‘better’ way to index everything.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
(Strange that this didn’t show up in my ‘mentions’—wonder what else I am not replying to—)
Even aside from any larger societal impact, I can’t say that anything I have done on social media has been nearly as worthwhile. The past year, since about March, I’ve committed to spending less time on social media, and my creative output is way up.
I think this is so encouraging—maybe the most encouraging thing one can say! Can you point to what is causing this? Is it the feeling of working for yourself, rather than—as you say—giving ‘free labor’ to the CorpASAs?
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
This is wild! I was recently having a discussion with another teacher about the similarities with gardening. One of the other helpful metaphors (for elementary teachers) is that the plants are kind of in their own world. Not that we’re not in their world at all and that we don’t relate to them, care about them, lift them up—but that I think they really just see each other when it comes down to it. Their social realm is very important to them and it’s kind of alien to us, which is just how it is.
But I also get the same feeling surveying a lush garden as I do when I step back and look at the whole class.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Haha—ok, well, I definitely own the ham and cheese! Am I close??
With my car, it depends on the legal jurisdiction, the name on the title for the vehicle, the ability of the government to enforce my ownership—and maybe ‘owning’ a car isn’t nearly as important as ‘controlling’ it.
I wonder if that might be the issue here with Micro.blog—perhaps Belle feels like she can’t ‘control’ her stuff enough. I guess I’m trying to draw a parallel between the public_html directory and Micro.blog. If a platform ultimately just feels like a folder that I can sync ‘in’ to and ‘out’ of—then I think it reaches the ideals of ‘ownership’ and ‘control’ on the Web. But that’s me—am I missing something?
(This is also clearing up why I’m seeing TiddlyWikis spring up—that’s a platform where EVERYTHING is local and is likeliest to have longevity because it doesn’t rely on ‘anyone’/‘anybiz’ else.)
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Yes, so—post everything you can ideally!
I tend to not post small comments there. If I did, I would post them to a personal sub (like /en/kickscondor or something).
For everything else, I stick to a few topics: /en/linking is used by Brad Enslen and I for discussion about finding blogs and the future of search engines. I post housekeeping stuff to /en/xyz. So, once you start posting regularly to a sub, others are more likely to join in.
Thankyou for asking! I have had a broken blog for a week, so that’s why this took so long. 😎
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.
Oh boy—man, I am sorry! FWIW I think you are doing great with micro.blog. I already have my own setup and I’m just glad I can still participate in the network from the outside. What a gift! I actually think you’ve figured out a great way to keep the Indieweb humming AND build a nice smaller network. You deserve a lot of encouragement—and Belle could use it, too, I’m sure. It’s difficult to build these things.
I think the larger problem right now is that there are so few good choices. This puts a lot of pressure on you and your team. But I think that your work could encourage more small networks like this—just as you said in your recent post. This all takes a lot of patience to wait out. Let’s hope you, Belle and the rest of us can see this through. Peace, brother.
This post accepts webmentions. Do you have the URL to your post?
You may also leave an anonymous comment. All comments are moderated.

glitchyowl, the future of 'people'.
jack & tals, hipster bait oracles.
maya.land, MAYA DOT LAND.
hypertext 2020 pals: h0p3 level 99 madman + ᛝ ᛝ ᛝ — lucid highly classified scribbles + consummate waifuist chameleon.
yesterweblings: sadness, snufkin, sprite, tonicfunk, siiiimon, shiloh.
surfpals: dang, robin sloan, marijn, nadia eghbal, elliott dot computer, laurel schwulst, subpixel.space (toby), things by j, gyford, also joe jenett (of linkport), brad enslen (of indieseek).
fond friends: jacky.wtf, fogknife, eli, tiv.today, j.greg, box vox, whimsy.space, caesar naples.
constantly: nathalie lawhead, 'web curios' AND waxy
indieweb: .xyz, c.rwr, boffosocko.
nostalgia: geocities.institute, bad cmd, ~jonbell.
true hackers: ccc.de, fffff.at, voja antonić, cnlohr, esoteric.codes.
chips: zeptobars, scargill, 41j.
neil c. "some..."
the world or cate le bon you pick.
all my other links are now at href.cool.






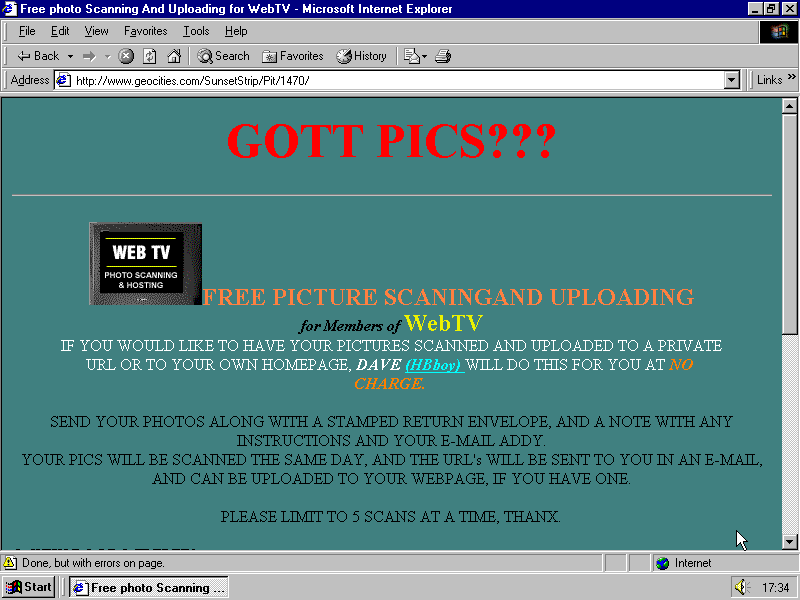{kind=link}
Reply:
I wonder how much you need to know about Dat. I think all you need to know is that it’s like a website Dropbox. You have a folder on your computer that contains your website—and when I visit your site I can choose to keep a copy on my machine.
So, basically, it’s like if Chrome allowed you to host a website. In Beaker you have a ‘Library’ page that shows all the websites you are also hosting.
The mouse pointer in this picture is pointing to the number 10—showing that ten folks out there have copies of Tara Vancil’s website that she is sharing.
This is the basic piece. Which is somewhat compelling.
But the amazing part is that you can actually run blogging software directly from inside Beaker. A simple version of this is dead-lite, for instance, but much more will become possible in time. (Good to see you. Have a nice weekend!)